(author: John Salatas)
1. Foreword
Currently Sphinx-4 uses a predefined dictionary for mapping words to sequence of phonemes. I propose modifications in the Sphinx-4 code that will enable it to use trained models (through some king of machine learning algorithm) to map letters to phonemes and thus map words to sequence of phonemes without the need of a predefined dictionary. A dictionary will be only used to train the required models.
2. Literature Review
2.1. Grapheme-to-Phoneme methods
Grapheme to Phoneme (G2P) (or Letter to Sound – L2S) conversion is an active research field with applications to both text-to-speech (TTS) and automated speech recognition (ASR) systems. There are many different approaches used for the G2S conversion proposed by different researchers.
Hein [1] proposes a method that use a feedforward neural network for the G2S conversion process and proposes a simple algorithm for the creation of the grapheme-to-phoneme matching database with a phonetic dictionary as input. The method has been tested in both English and German languages. 99.2% of 305000 entries of the German CELEX could be completely mapped and 91.8% of 59000 entries of the English PRONLEX.
Stoianov et al. [2] propose the use of Simple Recurrent Network (SRN) [3] for learning grapheme-to-phoneme mapping in Dutch. They conclude that SRN performs well on training and unseen test data sets even after very limited number of training epochs. Also, there were significant consistency and frequency effects on error.
Daelemans and Van Den Bosch [4] propose a data-oriented language-independent approach to grapheme-to-phoneme conversion problem. Their method takes as input a set of spelling words with their associative pronunciation, which do not have to be aligned, and produces as its output the phonetic transcription according to the implicit rules in the training dataset. The method is evaluated for the Dutch language with a 95,1% accuracy in unseen words.
Jouvet et al. [5] propose the combination of two g2p converters, one based on joint multigram model (JMM) [6] and one on conditional random fields (CRF) [7] and, furthermore, they evaluate the g2p conversion in a speech recognition context using French broadcast news data and cmusphinx.
The Joint-Multigram Model approach is a state of the art approach for grapheme-to-phoneme conversion [6]. The JMM approach relies on using joint sequences, where each joint sequence is actually composed of a sequence of graphemes and its associated sequence of phonemes. A language model is applied on the joint sequences. The training algorithm aims at determining the optimal set of joint sequences as well as the associated language model. The training proceeds in an incremental way. An initial pass creates a very simple model. Then each new training pass refines the model by enlarging the joint sequences whenever it is relevant to do so (i.e. it optimizes some training criteria). [5]
The CRF-based approach for grapheme-to-phoneme conversion [7],[8] is more recent than the JMM-based approach. It relies on the probabilistic framework and discriminative training offered by CRFs for labeling structured data such as sequences. The advantage of the CRF approach is its ability to handle various features, that is an arbitrary window length of letters, and possibly additional information such as word category. [5]
2.2. The CMU Sphinx-4 speech recognition system
Sphinx-4 [9],[10] is a flexible, modular and pluggable framework to help foster new innovations in the core research of hidden Markov model (HMM) recognition systems. The design of Sphinx-4 is based on patterns that have emerged from the design of past systems as well as new requirements based on areas that researchers currently want to explore. To exercise this framework, and to provide researchers with a ”research-ready” system, Sphinx-4 also includes several implementations of both simple and state-of-the-art techniques. The framework and the implementations are all freely available via open source. [9]
The Sphinx-4 architecture has been designed with a high degree of modularity. Figure 1 shows the overall architecture of the system. Even within each module shown in Figure 1, the code is extremely modular with easily replaceable functions. [10]
[caption id="attachment_320" align="aligncenter" width="428" caption="Figure 1: Architecture of the Sphinx-4 system. The main blocks are Frontend, Decoder and Knowledge base. Except for the blocks within the KB, all other blocks are independently replaceable software modules written in Java. Stacked blocks indicate multiple types which can be used simultaneously"]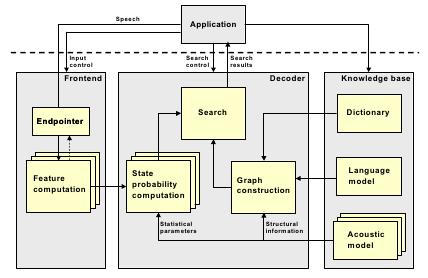 [/caption]
[/caption]
3. Initial Implementation Considerations
Regarding the CRF models, there is already a java implementation [11] which is based on the original CRF paper by J. Lafferty et al [12].
For the JMM models, there are many different approaches proposed [6], [13], [14] and all of them provide the implementation code (in C++/python) as free software available at [15], [16] and [17] respectively.
Another point regarding the JMM models, is the implementation of Weighted Finite State Transducers in java. Two possible approaches would be to a) either reimplement OpenFST Library [18] in java (it is written in C++) or b) investigate if the classes under the fst package [19] of the MARY Text-to-Speech System [20] can be easily integrated in cmusphinx, or if it can just be the basis for a new WFST implementation in Java.
4. Conclusion – Future work
The modular architecture of Sphinx-4 allows for experimentation in emerging areas of research and gives the ability to researchers to easily replace most of it's parts.
On a recent paper [21] Jouvet et al. propose the combination of two g2p converters, one based on joint multigram model (JMM) and one on conditional random fields (CRF). They evaluate the g2p conversion in a speech recognition context using French broadcast news data and cmusphinx.
During the Google Summer of Code 2012, I will follow a similar approach as in the above paper in order to evaluate and implement the necessary code for g2p conversion in sphinx-4.
You can follow my progress by subscribing to my project's blog feeds [22]
References
[1] H. U. Hein, “Automation of the training procedures for neural networks performing multi-lingual grapheme to phoneme conversion”, EUROSPEECH'99, pp. 2087-2090, 1999.
[2] I. Stoianov, L. Stowe, and J. Nerbonne, “Connectionist learning to read aloud and correlation to human data”, Proceedings of the 21st Annual Conference of the Cognitive Science Society. Hillsdale, NJ: Erlbaum, 1999.
[3] J.L. Elman, “Finding structure in time”, Cognitive Science, 14, pp. 213-252, 1990.
[4] W. Daelemans, A. V.D. Bosch, "Language-independent data-oriented grapheme-to-phoneme conversion", Progress in Speech Synthesis, pp. 77–89. New York, USA, 1997.
[5] D. Jouvet, D. Fohr, I. Illina, "Evaluating Grapheme-to-Phoneme Converters in Automatic Speech Recognition Context", IEE International Conference on Acoustics, 2012.
[6] M. Bisani, H. Ney, "Joint-sequence models for grapheme-to-phoneme conversion", Speech Communications, vol. 50, no. 5, 2008.
[7] D. Wang, S. King, "Letter-to-sound Pronunciation Prediction Using Conditional Random Fields", IEEE Signal Processing Letters, vol. 18, no. 2, pp. 122-125, 2011.
[8] I. Illina, D. Fohr & D. Jouvet, "Grapheme-to-Phoneme Conversion using Conditional Random Fields", in Proc. INTERSPEECH'2011, Florence, Italy, Aug. 2011.
[9] W. Walker, P. Lamere, P. Kwok, B. Raj, R. Singh, E. Gouvea, P. Wolf, and J. Woelfel, “Sphinx-4: A flexible open source framework for speech recognition”, Technical Report SMLI TR2004-0811, Sun Microsystems Inc., 2004.
[10] P. Lamere, P. Kwok, W. Walker, E. Gouvea, R. Singh, B. Raj, and P. Wolf, “Design of the CMU Sphinx-4 decoder”, Proceedings of the 8th European Conference on Speech Communication and Technology, Geneve, Switzerland, pp. 1181–1184, Sept. 2003.
[11] “CRF Project Page”, last accessed: 24/04/2012
[12] J. Lafferty, A. McCallum, F. Pereira, “Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data”, Proceedings of the International Conference on Machine Learning (ICML-2001),2001.
[13] “Phonetisaurus g2p tutorial”, last accessed: 25/04/2012
[14] S. Jiampojamarn, C. Cherry, G. Kondrak, “Joint Processing and Discriminative Training for Letter-to-Phoneme Conversion”, Proceeding of the Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (ACL-08: HLT), pp.905-913, Columbus, OH, June 2008.
[15] “Sequitur G2P, A trainable Grapheme-to-Phoneme converter”, last accessed: 25/04/2012
[16] “phonetisaurus: A WFST-driven Phoneticizer”, last accessed: 25/04/2012
[17] “DirecTL+ : String transduction model”, http://code.google.com/p/directl-p/ last accessed: 25/04/2012
[18] “OpenFST Library”, last accessed: 25/04/2012
[19] “Javadoc for package marytts.fst”, last accessed: 25/04/2012
[20] “The MARY Text-to-Speech System”, last accessed: 25/04/2012
[21] D. Jouvet, D. Fohr, I. Illina, "Evaluating Grapheme-to-Phoneme Converters in Automatic Speech Recognition Context", IEE International Conference on Acoustics, 2012
[22] “GSoC 2012: Letter to Phoneme Conversion in CMU Sphinx-4”, Project progress updates.