(author: John Salatas)
Foreword
Previous articles have shown how to use OpenGrm NGram Library for the encoding of joint multigram language models as WFST [1] and provided the code that simplifies and automates the fst model training [2]. As described in [1] the generated binary fst models with the procedures described in those articles are not directly usable from phonetisaurus [3] decoder.
This article will try to describe the compatibility issues in more details and provide some intuition on possible solutions and workarounds.
1. Open issues
Assuming a binary fst model, named cmudict.fst generated as described in [1], trying to evaluate it with phonetisaurus evaluate python script, results in the following error
$ ./evaluate.py --order 9 --modelfile cmudict.fst --testfile cmudict.dict.test.tabbed --prefix cmudict/cmudict
../phonetisaurus-g2p --model=cmudict.fst --input=cmudict/cmudict.words --beam=1500 --alpha=0.6500 --prec=0.8500 --ratio=0.7200 --order=9 --words --isfile > cmudict/cmudict.hyp
Symbol: 'A' not found in input symbols table.
Mapping to null...
Symbol: '4' not found in input symbols table.
Mapping to null...
Symbol: '2' not found in input symbols table.
Mapping to null...
Symbol: '1' not found in input symbols table.
Mapping to null...
Symbol: '2' not found in input symbols table.
Mapping to null...
Symbol: '8' not found in input symbols table.
Mapping to null...
sh: line 1: 18788 Segmentation fault ../phonetisaurus-g2p --model=cmudict.fst --input=cmudict/cmudict.words --beam=1500 --alpha=0.6500 --prec=0.8500 --ratio=0.7200 --order=9 --words --isfile > cmudict/cmudict.hyp
Words: 0 Hyps: 0 Refs: 13328
Traceback (most recent call last):
File "./evaluate.py", line 124, in
mbrdecode=args.mbrdecode, beam=args.beam, alpha=args.alpha, precision=args.precision, ratio=args.ratio, order=args.order
File "./evaluate.py", line 83, in evaluate_testset
PERcalculator.compute_PER_phonetisaurus( hypothesisfile, referencefile, verbose=verbose )
File "calculateER.py", line 333, in compute_PER_phonetisaurus
assert len(words)==len(hyps) and len(hyps)==len(refs)
AssertionError
2. Disussion on open issues
In order to investigate the error above, a simple aligned corpus was created as below
a}a b}b
a}a
a}a c}c
a}a b}b c}c
a}a c}c
b}b c}c
This simple corpus was used as input to both ngram and phonetisaurus model training procedures [1], [3] and the generated fst model (binary.fst) was visualized as follows
$ fstdraw binary.fst binary.dot
$ dot -Tps binary.dot > binary.ps
the generated two postscript outputs, using phonetisaurus and ngram respectively, are shown in the following figures:
[caption id="attachment_454" align="aligncenter" width="517" caption="Figure 1: Visualization of the fst model generated by phonetisaurus"]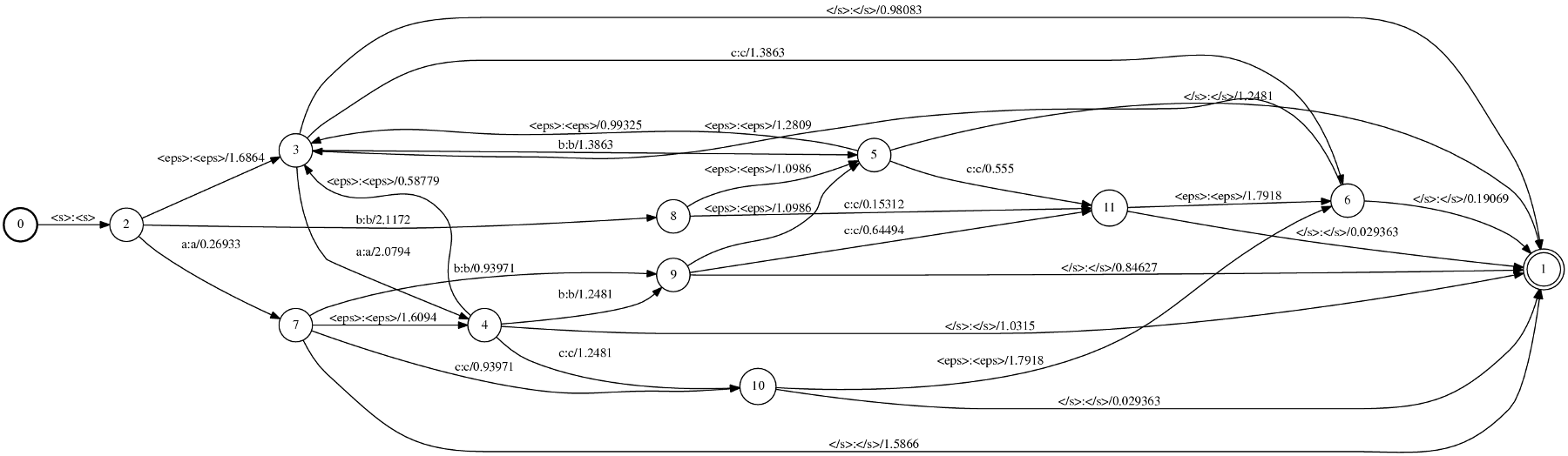 [/caption]
[/caption]
[caption id="attachment_459" align="aligncenter" width="517" caption="Figure 2: Visualization of the fst model generated by ngram"]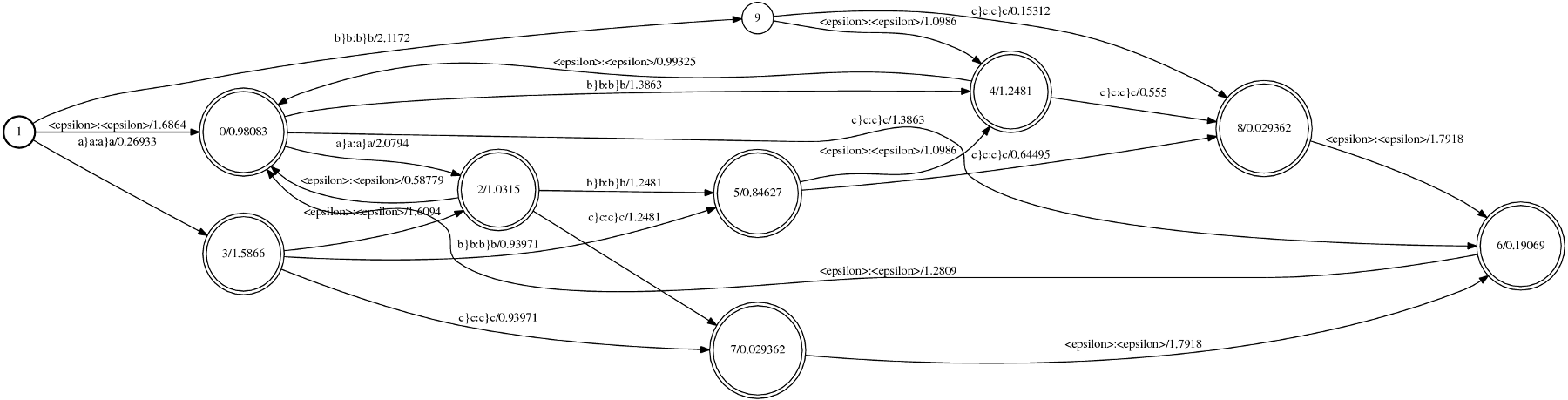 [/caption]
[/caption]
By studying the two figures above the first obvious conclusion is that the model generated with ngram do not distinguish between graphemes (input label) and phonemes (output label), but it uses the joint multigram (eg “a}a”) as both input and output label.
Another obvious difference between the two models is the starting and final state(s). Phonetisaurus models have a fixed starting state with a single outgoing arc with labels : labels in all incoming arcs. and no weight. Furthermore, in phonetisaurus model there exist only a single final state with :
3. Possible solutions and workarounds
[1] already presents a workaround to bypass the compatibility issues described in the previous section. We can simply export the ngram generated binary fst model to an ARPA format with:
$ ngramprint --ARPA binary.fst > export.arpa
and the use phonetisaurus' arpa2fst convert utility to regenerate a new binary fst model compatible with phonetisaurus' decoder.
$ phonetisaurus-arpa2fst –input=export.arpa
Although this is a straightforward procedure, a more elegant solution would be to iterate in all arcs and manually break apart the grapheme/phoneme joint multigram labels to input/output labels accordingly. A final step, if necessary, would be to add the start and single final state in the ngram generated fst model.
4. Conclusion – Future work
This article tried to provide some intuition on the compatibility issues between ngram and phonetisaurus models and also to possible solutions and workarounds. As explained in the previous section, there is already a straightforward procedure to overcome these issues (export to ARPA format and regenerate the binary model), but in any case it is worth to try the relabeling approach described also in the previous section.
References
[1] Using OpenGrm NGram Library for the encoding of joint multigram language models as WFST.
[2] Automating the creation of joint multigram language models as WFST.
[3] Phonetisaurus: A WFST-driven Phoneticizer – Framework Review