Training Acoustic Models On long Audio Files
Abstract
The current implementation of SphinxTrain processes audio files of up to 5 minutes approximately. The limitation is due to the memory amount and the computer time available. Possibility of training on long audio files such as audio books and radio broadcasts without the need for prior segmentation could radically simplify the training process while also making it much more efficient.
Current graphical hardware allows achieving computational power unavailable for general-purpose processors. The aim of this project is to enable the acoustic model training on long audio files by the utilization of NVIDIA CUDA architecture. With the usage of GPGPU (general-purpose computing on graphics processing units), the memory becomes the constraint rather than the amount of computation. The implementation will therefore incorporate the technique to reduce the memory requirements of Baum-Welch algorithm.
CUDA
CUDA (Compute Unified Device Architecture) [1] is NVIDIA’s parallel computing architecture and development platform. CUDA represents a SIMD (single instruction, multiple data) execution model, which means that multiple processing elements perform the same operation on multiple data simultaneously.
CUDA technology is quite universal, however for the parallel hardware to be properly utilized, CUDA puts some restrictions on the programmer. This includes the absence of recursion, need for memory coalescence and avoidance of thread branching. Some of these limitations have smaller impact on performance on the latest CUDA hardware.
HMM (Hidden Markov Model) training algorithms - forward algorithm, Viterbi algorithm and Baum-Welch algorithm - are examples of the dynamic programming approach. It has been shown that they scale to CUDA very naturally with the forward and B-W algorithms speedup of 800x and 200x respectively. [2] Moreover, CUDA offers further optimizations which were not used in the study, such as use of texture memory. The optimization of HMM training algorithms will be one of the main tasks of this projects.
Memory Optimizations
The desire for training on long audio files brings the need for memory optimizations. There are techniques that reduce the space complexity of HMM training algorithms from O(T) to O(sqrt(T)) with respect to length of the data sequence. In [3] such a technique using “checkpoints” is discussed. While bringing some (10%) slowdown for small inputs and HMM sizes, it is shown also to bring a huge speedup for large inputs causing excessive paging when using standard method. Implementation of this kind of optimization will be part of the task.
Project Schedule
- Implementation of SphinxTrain speedup and memory optimizations
- implement reduced memory HMM training and classification algorithms
- Porting SphinxTrain algorithms to CUDA
- port the forward algorithm to CUDA
- port the Viterbi algorithm to CUDA
- port the Baum-Welch algorithm to CUDA
- evaluate the resulting speedup and memory requirements
- Enable SphinxTrain to process long input audio files
- modify training scripts to handle long input audio files
- modify feature extraction to use text alignment markup
- modify training database format
Related Sources
Work Update
A collection of audio files 5 to 10 minutes long have been turned into CMUSphinx training database (//’rita’//) in order to determine possible issues when training on longer recordings. A branch long-audio-training was created in CMUSphinx SVN repository.
Memory Size Limits
First finding was that the current version of SphinxTrain does not take long transcription sentences into account. The training process failed at the baum-welch step due to unsuccessful word lookup in lexicon. This was caused by sentence and the word truncation at an arbitrary limit of 8192 characters. First change commited was the fix for the sentence-length problem. As the source of limitations was identified the read_line function. The modification got rid of the read_line function making use of the lineiter_* set of functions from sphinxbase. lineiter_* interface was modified to provide original read_line functions such as comments skipping and whitespace trimming.
Memory Requirements
Another result of the experiments is that the training process is rather memory demanding. Presently, the training consumes about 1.7GB of RAM when processing ~5 minutes-long recording and over 4GB of RAM when processing ~10 minutes-long recording. The memory management of the current SphinxTrain version was thoroughly examined by the Valgrind family tools.
An interesting result was that the training on 42 minutes of short audio files (each few seconds long) took about the same as training on a single file 5:31 minutes long. This suggests that the memory demands of the SphinxTrain is no-way linear to T and shows the necessity of identification of existing issues and implementation of memory optimization techniques.
During the experiments also the problem with extensive reallocation was found. This was cca 760,000 of ckd_realloc function calls in one-pass Baum-Welch training on an4 database. Initial active state set allocation size was repeatedly set too low and after that vastly insreased (by about 1.3 GB on rita database) by the step of a few bytes. The solution was to increase the allocated space by a quadratic step instead of linear.The modification reduced the reallocation to the 18,500 function calls on an4 database, thus by the factor of about 40. The tradeof was slight increase in the total amount of memory allocated from 5.7 MB to 6.2 MB and from 1.4 GB to 1.7 GB on an4 and rita databases respectively. The multiplication factor was set to 2 but this was arbitrary and can be subject to optimization. In theory this modification could also reduce the running time of the algorithm but significant reduce of time was not measured (approximately 8 minutes +- few seconds in all cases - an4 & rita with and without the modification).
The Baum-Welch implementation was also examined for memory leaks. This has shown not to be a big issue. Some memory leaks were found but nothing significant - under 1 MB in all cases. It was concluded that the reduced space technique implementation is necessary.
The way of reducing the memory demands is a checkpoint method[3]. The most recently the forward algorithm was changed to produce the reduced active alpha matrix in addition to the original behaviour. The idea is to save alpha values only for certain time points. In particular this is the multiples of sqrt(T), although the method allows parametrisation for any integer-root of T. The tradeof is increase in the computation length by the same factor. Following steps are the modification of backward and Viterbi algorithms to be able to recalculate the missing values.
Reduced Baum-Welch Implementation Summary
In the past weeks the reduced Baum-Welch computation has been implemented into the SphinxTrain. This is a major step on the way to enable the CMUSphinx to train on long audio files. A summary and discussion of the results are following.
Method
The approach is essentially the same as 2-level checkpoint method described in [3]. In the classical implementation the Forward, Backward and Viterbi algorithms work with complete alpha matrix. For the optimization these algorithms were changed in the following way:
-
Reduced forward algorithm stores alpha values only for the checkpoints instead of all time frames. The segment of actual alpha values then can be recomputed given a checkpoint - it’s first time frame. The number of checkpoint is derived from the segment size, which is a parameter.
-
Local forward method was created to recompute the values for the segment from a checkpoint.
-
Backward update process the alpha matrix from the end. It recomputes the segment values via the local forward when needed.
-
As Viterbi algorithm is embedded in the forward-pass in SphinxTrain, only the backtracking had to be changed. It was modified in the similar way as backward update.
Although the segment size and thus checkpoints count can be set arbitrarily,
the most reasonable value for both is sqrt(T), where T is the length of
the observation sequence (this is with the respect to the memory demands). This
in theory reduces the asymptotic space complexity of the three algorithms to
the square root function of observation sequence length. In reality the savings
are somewhat smaller, as there is a need for two matrix instances in every
method, which processes alpha values - reduced (checkpoint) matrix and local
(segment) matrix. This approach is also expected to slow down the training
process approximately by the factor of 2 irrespective of the segment length,
because every alpha value is essentially computed twice.
Results
The modification was tested on two training databases - An4, representing a
short training recordings (few seconds) and Rita, consisting of one long (5+
minutes recording). The memory consumption was measured by Unix command
time with verbose (-v) option.
The test shows, that the Baum-Welch step is by far the most memory-intensive
among the all training steps as defined in scripts_pl directory (peaks
between the steps 20. and 55.):
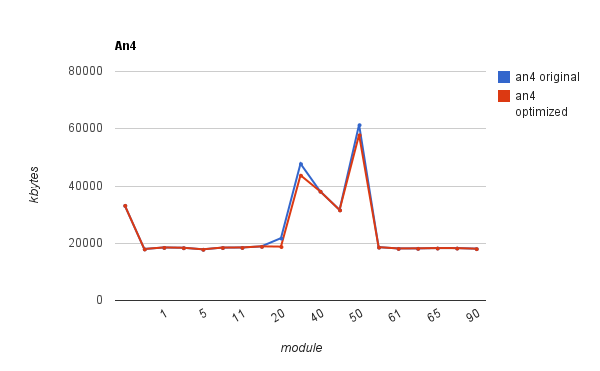
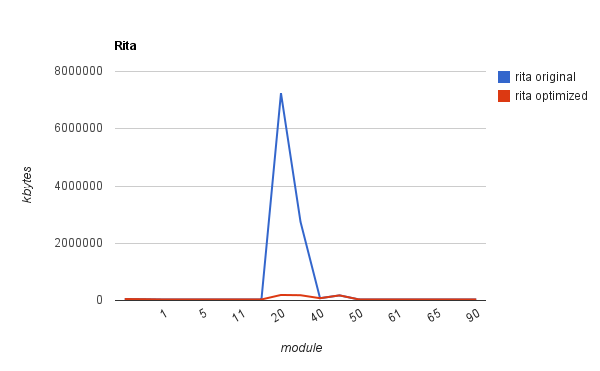
The pictures show also the resulting improvement in the Baum-Welch memory demands. (The memory demands of other steps were unaffected.) Here are more detailed pictures:
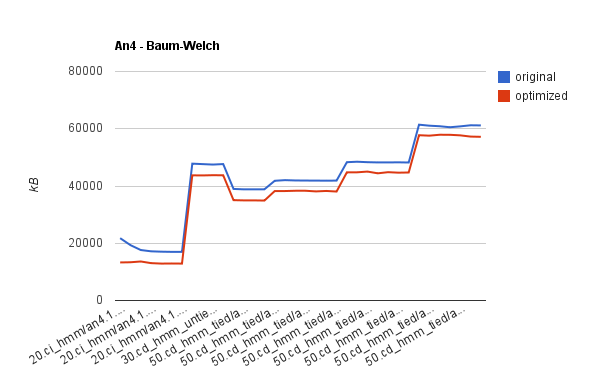
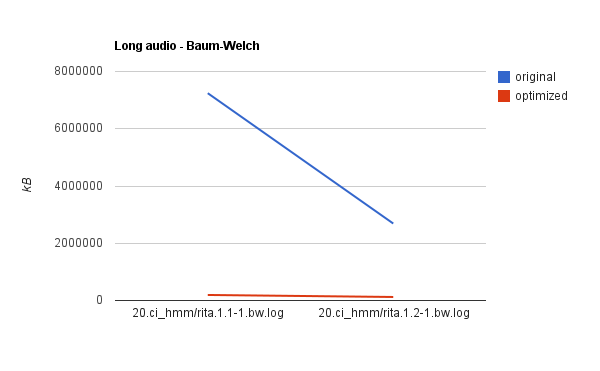
They clearly show the small improvement in the training on short audio (an4) but a huge improvement in the training on long audio (Rita). The actual reduction of memory consumption on Rita is from 6.8GB to 175MB and from 2.5GB to 100MB approximately. The time demands increased about 2 times, which is as expected.
Note: The computation on long audio files kept failing due to alignment error. Because of that the subsequent steps were skipped (or also failed) and the values measured for these modules are not representative. The problem with long audio alignment is addressed by a separate project (see longaudioalignment).
— //Michal Krajňanský 2011/07/13 10:26//