Building an application with sphinx4
Caution!
This tutorial uses the sphinx4 API from the 5 pre-alpha release.
The API described here is not supported in earlier versions.
Overview
Sphinx4 is a pure Java speech recognition library. It provides a quick and easy API to convert the speech recordings into text with the help of CMUSphinx acoustic models. It can be used on servers and in desktop applications. Besides speech recognition, Sphinx4 helps to identify speakers, to adapt models, to align existing transcription to audio for timestamping and more.
Sphinx4 supports US English and many other languages.
Using sphinx4 in your projects
As any library in Java all you need to do to use sphinx4 is to add the jars to the dependencies of your project and then you can write code using the API.
The easiest way to use sphinx4 is to use modern build tools like Apache Maven or Gradle. Sphinx-4 is available as a maven package in the Sonatype OSS repository.
In gradle you need the following lines in build.gradle:
repositories {
mavenLocal()
maven { url "https://oss.sonatype.org/content/repositories/snapshots" }
}
dependencies {
compile group: 'edu.cmu.sphinx', name: 'sphinx4-core', version:'5prealpha-SNAPSHOT'
compile group: 'edu.cmu.sphinx', name: 'sphinx4-data', version:'5prealpha-SNAPSHOT'
}
To use sphinx4 in your maven project specify this repository in your pom.xml:
<project>
...
<repositories>
<repository>
<id>snapshots-repo</id>
<url>https://oss.sonatype.org/content/repositories/snapshots</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
...
</project>
Then add sphinx4-core to the project dependencies:
<dependency>
<groupId>edu.cmu.sphinx</groupId>
<artifactId>sphinx4-core</artifactId>
<version>5prealpha-SNAPSHOT</version>
</dependency>
Add sphinx4-data to the dependencies as well if you want to use the default
US English acoustic and language models:
<dependency>
<groupId>edu.cmu.sphinx</groupId>
<artifactId>sphinx4-data</artifactId>
<version>5prealpha-SNAPSHOT</version>
</dependency>
Many IDEs like Eclipse, Netbeans or Idea have support for Gradle either through plugins or with built-in features. In that case you can just include sphinx4 libraries into your project with the help of your IDE. Please check the relevant part of your IDE documentation, for example the IDEA documentation on Gradle.
You can also use Sphinx4 in a non-maven project. In this case you need to download the jars from the repository manually. You might also need to download the dependencies (which we try to keep small) and include them in your project. You need the sphinx4-core jar and the sphinx4-data jar if you are going to use US English acoustic model:
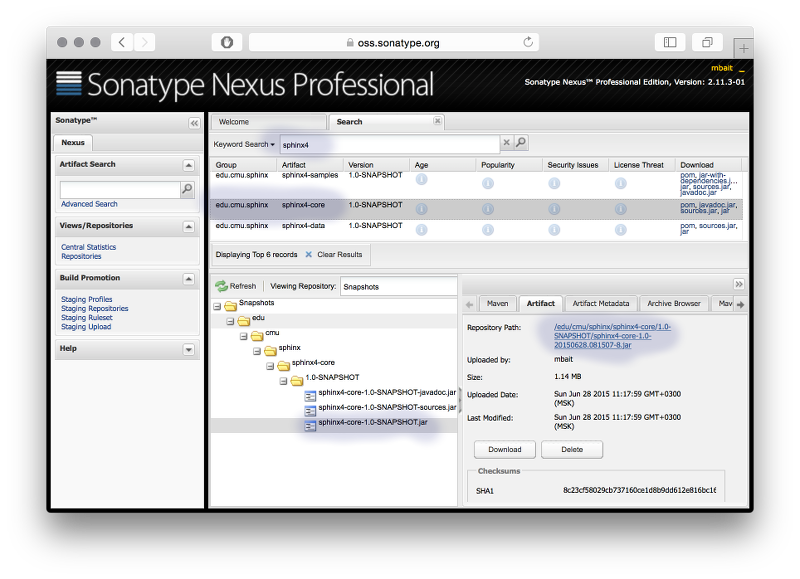
Here is an example for how to include the jars in Eclipse:
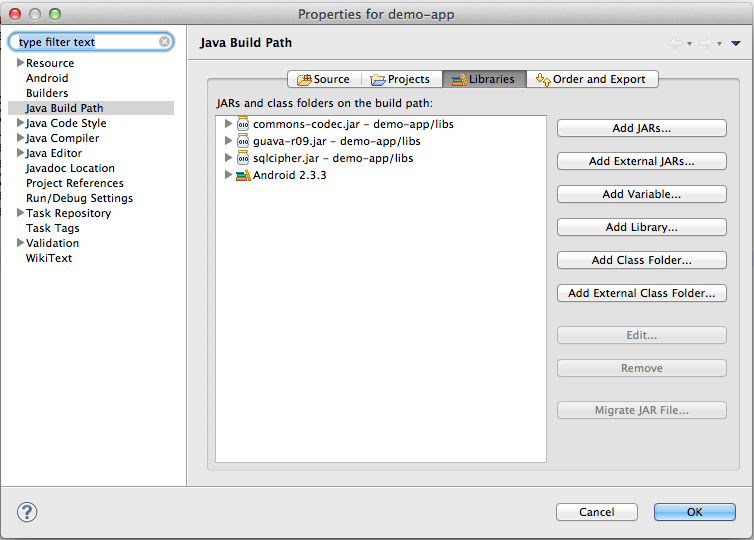
Basic Usage
To quickly start with sphinx4, create a java project as described above, add the required dependencies and type the following simple code:
package com.example;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
import edu.cmu.sphinx.api.Configuration;
import edu.cmu.sphinx.api.SpeechResult;
import edu.cmu.sphinx.api.StreamSpeechRecognizer;
public class TranscriberDemo {
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
configuration.setAcousticModelPath("resource:/edu/cmu/sphinx/models/en-us/en-us");
configuration.setDictionaryPath("resource:/edu/cmu/sphinx/models/en-us/cmudict-en-us.dict");
configuration.setLanguageModelPath("resource:/edu/cmu/sphinx/models/en-us/en-us.lm.bin");
StreamSpeechRecognizer recognizer = new StreamSpeechRecognizer(configuration);
InputStream stream = new FileInputStream(new File("test.wav"));
recognizer.startRecognition(stream);
SpeechResult result;
while ((result = recognizer.getResult()) != null) {
System.out.format("Hypothesis: %s\n", result.getHypothesis());
}
recognizer.stopRecognition();
}
}
This simple code snippet transcribes the file test.wav – just make sure it
exists in the project root.
There are several high-level recognition interfaces in sphinx4:
- LiveSpeechRecognizer
- StreamSpeechRecognizer
- SpeechAligner
For most of the speech recognition jobs high-level interfaces should be sufficient. Basically, you will only have to setup four attributes:
- Acoustic model
- Dictionary
- Grammar/Language model
- Source of speech
The first three attributes are set up using a Configuration object which is
then passed to a recognizer. The way to connect to a speech source depends on
your concrete recognizer and usually is passed as a method parameter.
Configuration
A Configuration is used to supply the required and optional attributes
to the recognizer.
Configuration configuration = new Configuration();
// Set path to acoustic model.
configuration.setAcousticModelPath("resource:/edu/cmu/sphinx/models/en-us/en-us");
// Set path to dictionary.
configuration.setDictionaryPath("resource:/edu/cmu/sphinx/models/en-us/cmudict-en-us.dict");
// Set language model.
configuration.setLanguageModelPath("resource:/edu/cmu/sphinx/models/en-us/en-us.lm.bin");
LiveSpeechRecognizer
The LiveSpeechRecognizer uses a microphone as the speech source.
LiveSpeechRecognizer recognizer = new LiveSpeechRecognizer(configuration);
// Start recognition process pruning previously cached data.
recognizer.startRecognition(true);
SpeechResult result = recognizer.getResult();
// Pause recognition process. It can be resumed then with startRecognition(false).
recognizer.stopRecognition();
StreamSpeechRecognizer
The StreamSpeechRecognizer uses an InputStream as the speech source. You can
pass the data from a file, a network socket or from an existing byte array.
StreamSpeechRecognizer recognizer = new StreamSpeechRecognizer(configuration);
recognizer.startRecognition(new FileInputStream("speech.wav"));
SpeechResult result = recognizer.getResult();
recognizer.stopRecognition();
Please note that the audio for this decoding must have one of the following formats:
RIFF (little-endian) data, WAVE audio, Microsoft PCM, 16 bit, mono 16000 Hz
or
RIFF (little-endian) data, WAVE audio, Microsoft PCM, 16 bit, mono 8000 Hz
The decoder does not support other formats. If the audio format does not match, you will not get any results. This means, you need to convert your audio to a proper format before decoding. E.g. if you want to decode audio in telephone quality with a sample rate of 8000 Hz, you would need to call
configuration.setSampleRate(8000);
You can retreive multiple results until the end of the file is reached:
while ((result = recognizer.getResult()) != null) {
System.out.println(result.getHypothesis());
}
SpeechAligner
A SpeechAligner time-aligns text with audio speech.
SpeechAligner aligner = new SpeechAligner(configuration);
aligner.align(new URL("101-42.wav"), "one oh one four two");
SpeechResult
A SpeechResult provides access to various parts of the recognition result,
such as the recognized utterance, a list of words with timestamps, the
recognition lattice, etc.:
// Print utterance string without filler words.
System.out.println(result.getHypothesis());
// Get individual words and their times.
for (WordResult r : result.getWords()) {
System.out.println(r);
}
// Save lattice in a graphviz format.
result.getLattice().dumpDot("lattice.dot", "lattice");
Demos
A number of sample demos are included in the sphinx4 sources in order to give you an understanding how to run sphinx4. You can run them from the sphinx4-samples jar:
- Transcriber - demonstrates how to transcribe a file
- Dialog - demonstrates how to lead a dialog with a user
- SpeakerID - speaker identification
- Aligner - demonstration of audio to transcription timestamping
If you are going to start with a demo please do not modify the demo inside the sphinx4 sources. Instead, copy the code into your project and modify it there.
Building from source
If you want to develop sphinx4 itself you might want to build it from source.
Sphinx4 uses the Gradle build system. In order to compile
and install everything, including the dependencies, simply type ‘gradle build’
in the root directory.
If you are going to use an IDE, make sure it supports Gradle projects. Then simply import the sphinx4 source tree.
Troubleshooting
You might experience the one or the other problem while using sphinx4. Please check the FAQ first before asking any new questions on the forum.
In case you have issues with the accuracy, you need to provide the audio recording you are trying to recognize along with all models you use. Additionally, you need to describe in which way your results differ from your expectations.