Unsupervised Training Of Acoustic Models
Introduction
Quality of speech recognition is closely related to the quality of language and acoustic models used. Currently, acoustic models are trained mostly in supervised training mode, in which large quantities of audio data along with it’s transcribed data provides statistical information about features corresponding to individual phones. CMUSphinx wiki describes a supervised training procedure in detail here. In supervised training, the quality of resulting model is depends on the size of corpus and extent to which it describes speech of the target language ( to be extensive, the corpus should contain utterances containing most of the words from target language ). However supervised training is efficient, creating large enough databases for training in most languages is a costly affair. On the other hand, medium or low quality audio and text data is readily available for almost all languages. Hence, it is of interest to study effects of accurate model training from such data.
Literature Survey
A quick way of generating an acoustic model for a language when acoustic model for another similar* language is available is using Cross Language Bootstrapping (described in http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.163.7997 ). The methodology employed here is of using a phoneset to phoneset mapping that maps phones of base language to the phones of the target language based on their similarity.
- Similarity of languages here is based on the similarity underlying phone set
of base and target languages.
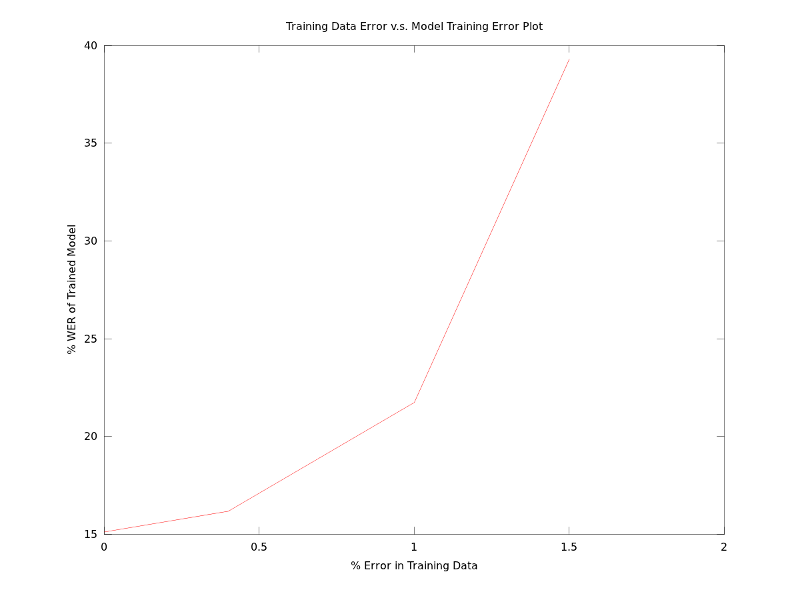
Experiments to study effect of error in training data