Porting openFST to java: Part 3
(author: John Salatas)
Foreword
This article, the third in a series regarding, porting openFST to java, introduces the latest update to the java code, which resolve the previously raised issues regarding the java fst architecture in general and its compatibility with the original openFST format for saving models. [1]
1. Code Changes
1.1. Simplified java generics usage
As suggested in [1], the latest java fst code revision (11456), available in the cmusphinx SVN Repository [2], assumes only the base Weight class and modifies the State, Arc and Fst classes definition to simply use a type parameter.
The above modifications provide an easier to use api. As an example the construction of a basic FST in the class edu.cmu.sphinx.fst.demos.basic.FstTest is simplified as follows
...
Fst fst = new Fst();
// State 0
State s = new State();
s.AddArc(new Arc(new Weight(0.5), 1, 1, 1));
s.AddArc(new Arc(new Weight(1.5), 2, 2, 1));
fst.AddState(s);
// State 1
s = new State();
s.AddArc(new Arc(new Weight(2.5), 3, 3, 2));
fst.AddState(s);
// State 2 (final)
s = new State(new Weight(3.5));
fst.AddState(s);
...
1.2. openFST models compatibilty
Besides the simplified java generics usage above, the most important change is the code to load an openFST model in text format and convert it to a java fst serialized model. This is achieved also in the latest java fst code revision (11456) [2].
2. Converting openFST models to java
2.1. Installation
The procedure below is tested on an Intel CPU running openSuSE 12.1 x64 with gcc 4.6.2, Oracle Java Platform (JDK) 7u5, and ant 1.8.2.
In order to convert an openFST model in text format to java fst model, the first step is to checkout from the cmusphinx SVN repository the latest java fst code revision:
# svn co https://cmusphinx.svn.sourceforge.net/svnroot/cmusphinx/branches/g2p/fst
Next step is to build the java fst code
cd fst
# ant jar
Buildfile:
jar:
build-subprojects:
init:
[mkdir] Created dir:
build-project:
[echo] fst:
[javac]
[javac] Compiling 10 source files to
[javac]
build:
[jar] Building jar:
BUILD SUCCESSFUL
Total time: 2 seconds
#
2.2. Usage
Having completed the installation as described above, and trained an openfst model named binary.fst as described in [3], with the latest model training code revision (11455) [4] the model is also saved in the openFST text format in a file named binary.fst.txt. The conversion to a java fst model is performed using the openfst2java.sh which can be found in the root directory of the java fst code. The openfst2java.sh accepts two parameters being the openfs input text model and the java fst output model as follows:
# ./openfst2java.sh binary.fst.txt binary.fst.ser
Parsing input model...
Saving as binary java fst model...
Import completed.
Total States Imported: 1091667
Total Arcs Imported: 2652251
#
The newly generated binary.fst.ser model can then be loaded in java, as follows:
try {
Fst fst = (Fst) Fst.loadModel("binary.fst.ser");
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
3. Performance: Memory Usage
Testing the conversion and loading of the cmudict.fst model generated in [3], reveal that the conversion task requires about 1.0GB and the loading of the converted model requires about 900MB of RAM.
4. Conclusion – Future Works
Having the ability to convert and load an openFST model in java, takes the “Letter to Phoneme Conversion in CMU Sphinx-4” project to the next step, which is the port of phonetisaurus decoder to java which will eventually lead to its integration with cmusphinx 4.
A major concern at this point is the high memory utilization while loading large models. Although it is expected for java applications to consume more memory compared to a similar C++ application, this could be a problem especially when running in low end machines and needs further investigation and optimization (if possible).
References
[1] Porting openFST to java: Part 2
[2] Java fst SVN (Revision 11456)
[3] Automating the creation of joint multigram language models as WFST: Part 2
Automating the creation of joint multigram language models as WFST: Part 2
(author: John Salatas)
Foreword
This a article presents an updated version of the model training application originally discussed in [1], considering the compatibility issues with phonetisaurus decoder as presented in [2]. The updated code introduces routines to regenerate a new binary fst model compatible with phonetisaurus’ decoder as suggested in [2] which will be reviewed in the next section.
1. Code review
The basic code for the model regeneration is defined in train.cpp in procedure
void relabel(StdMutableFst *fst, StdMutableFst *out, string eps, string skip, string s1s2_sep, string seq_sep);
where fst and out are the input and output (the regenerated) models respectively.
In the first initialization step is to generate new input, output and states SymbolTables and add to output the new start and final states [2].
Furthermore, in this step the SymbolTables are initialized. Phonetisauruss decoder requires the symbols eps, seq_sep, “
” and “” to be in keys 0, 1, 2, 3, 4 accordingly.
void relabel(StdMutableFst *fst, StdMutableFst *out, string eps, string skip, string s1s2_sep, string seq_sep) {
ArcSort(fst, StdILabelCompare());
const SymbolTable *oldsyms = fst->InputSymbols();
// Uncomment the next line in order to save the original model
// as created by ngram
// fst->Write("org.fst");
// generate new input, output and states SymbolTables
SymbolTable *ssyms = new SymbolTable("ssyms");
SymbolTable *isyms = new SymbolTable("isyms");
SymbolTable *osyms = new SymbolTable("osyms");
out->AddState();
ssyms->AddSymbol("s0");
out->SetStart(0);
out->AddState();
ssyms->AddSymbol("f");
out->SetFinal(1, TropicalWeight::One());
isyms->AddSymbol(eps);
osyms->AddSymbol(eps);
//Add separator, phi, start and end symbols
isyms->AddSymbol(seq_sep);
osyms->AddSymbol(seq_sep);
isyms->AddSymbol("");
osyms->AddSymbol("");
int istart = isyms->AddSymbol("");");
int iend = isyms->AddSymbol("
int ostart = osyms->AddSymbol("");");
int oend = osyms->AddSymbol("
out->AddState();
ssyms->AddSymbol("s1");
out->AddArc(0, StdArc(istart, ostart, TropicalWeight::One(), 2));
...
In the main step, the code iterates through each State of the input model and adds each one to the output model keeping track of old and new state_id in ssyms SymbolTable.
In order to transform to an output model with a single final state [2] the code checks if the current state is final and if it is, it adds an new arc connecting from the current state to the single final one (state_id 1) with label “:” and weight equal to the current state's final weight. It also sets the final weight of current state equal to TropicalWeight::Zero() (ie it converts the current state to a non final).
...
for (StateIterator siter(*fst); !siter.Done(); siter.Next()) {
StateId state_id = siter.Value();
int64 newstate;
if (state_id == fst->Start()) {
newstate = 2;
} else {
newstate = ssyms->Find(convertInt(state_id));
if(newstate == -1 ) {
out->AddState();
ssyms->AddSymbol(convertInt(state_id));
newstate = ssyms->Find(convertInt(state_id));
}
}
TropicalWeight weight = fst->Final(state_id);
if (weight != TropicalWeight::Zero()) {
// this is a final state
StdArc a = StdArc(iend, oend, weight, 1);
out->AddArc(newstate, a);
out->SetFinal(newstate, TropicalWeight::Zero());
}
addarcs(state_id, newstate, oldsyms, isyms, osyms, ssyms, eps, s1s2_sep, fst, out);
}
out->SetInputSymbols(isyms);
out->SetOutputSymbols(osyms);
ArcSort(out, StdOLabelCompare());
ArcSort(out, StdILabelCompare());
}
Lastly, the addarcs procuder is called in order to relabel the arcs of each state of the input model and add them to the output model. It also creates any missing states (ie missing next states of an arc).
void addarcs(StateId state_id, StateId newstate, const SymbolTable* oldsyms, SymbolTable* isyms,
SymbolTable* osyms, SymbolTable* ssyms, string eps, string s1s2_sep, StdMutableFst *fst,
StdMutableFst *out) {
for (ArcIterator aiter(*fst, state_id); !aiter.Done(); aiter.Next()) {
StdArc arc = aiter.Value();
string oldlabel = oldsyms->Find(arc.ilabel);
if(oldlabel == eps) {
oldlabel = oldlabel.append("}");
oldlabel = oldlabel.append(eps);
}
vector tokens;
split_string(&oldlabel, &tokens, &s1s2_sep, true);
int64 ilabel = isyms->AddSymbol(tokens.at(0));
int64 olabel = osyms->AddSymbol(tokens.at(1));
int64 nextstate = ssyms->Find(convertInt(arc.nextstate));
if(nextstate == -1 ) {
out->AddState();
ssyms->AddSymbol(convertInt(arc.nextstate));
nextstate = ssyms->Find(convertInt(arc.nextstate));
}
out->AddArc(newstate, StdArc(ilabel, olabel, (arc.weight != TropicalWeight::Zero())?arc.weight:TropicalWeight::One(), nextstate));
//out->AddArc(newstate, StdArc(ilabel, olabel, arc.weight, nextstate));
}
}
2. Performance – Evaluation
In order to evaluate the perfomance of the model generated with the new code. A new model was trained with the same dictionaries as in [4]
# train/train --order 9 --smooth "kneser_ney" --seq1_del --seq2_del --ifile cmudict.dict.train --ofile cmudict.fst
and evaluated with phonetisaurus evaluate script
# evaluate.py --modelfile cmudict.fst --testfile ../cmudict.dict.test --prefix cmudict/cmudict
Mapping to null...
Words: 13335 Hyps: 13335 Refs: 13335
######################################################################
EVALUATION RESULTS
----------------------------------------------------------------------
(T)otal tokens in reference: 84993
(M)atches: 77095 (S)ubstitutions: 7050 (I)nsertions: 634 (D)eletions: 848
% Correct (M/T) -- %90.71
% Token ER ((S+I+D)/T) -- %10.04
% Accuracy 1.0-ER -- %89.96
--------------------------------------------------------
(S)equences: 13335 (C)orrect sequences: 7975 (E)rror sequences: 5360
% Sequence ER (E/S) -- %40.19
% Sequence Acc (1.0-E/S) -- %59.81
######################################################################
3. Conclusions – Future work
The evaluation results in cmudict dictionary, are a little bit worst than using the command line procedure in [4]. Although the difference doesn't seem to be important, it needs a further investigation. For that purpose and for general one can uncomment the line fst->Write("org.fst"); in the relabel procedure as depicted in a previous section, in order to have the original binary model saved in a file called “org.fst”.
Next steps would probably be to write code in order to load the binary model in java code and to port the decoding algorithm along with the required fst operations to java and eventually integrate it with CMUSphinx.
References
[1] Automating the creation of joint multigram language models as WFST
[2] Compatibility issues using binary fst models generated by OpenGrm NGram Library with phonetisaurus decoder
[3] fstinfo on models created with opengrm
[4] Using OpenGrm NGram Library for the encoding of joint multigram language models as WFST
Hyperstring and Language Model FSA
(author: Alexandru Tomescu)
Foreword
As part of the PostProcessing Framework task of capitalization and punctuation recovery I am using Finite State Automata (FSA) to model hyperstrings ( all written forms of a text) and Language Models. These will be composed and a best-path search in the resulting FSA will output the best version (capitalized and punctuated) of a string.
Hyperstring FSA
The hyperstring FSA is composed from a string (i.e. "This is exciting") and considers all the possible written forms of the string.
S0 --- (This, this, THIS) ---> T0 --- (
, , ) ---> S1 --- (Is, is, IS) ---> T1 --- ( , , ) ---> S2 --- (Exciting, exciting, EXCITING) ---> T2 --- ( , , ) ---> S3
[caption id="" align="aligncenter" width="612" caption="Hyperstring FST"] [/caption]
[/caption]
S0 is the start state and S3 is the final state. Transitions between Si and Ti contain words and transitions between Ti and Ti+1 contain punctuation marks.
In the project this is represented by the FSA object which is constructed with the String we want to model and a boolean value which states if we also want punctuation added between transitions. If not the FSA will look like this:
S0 --- (This, this, THIS) ---> S1 --- (Is, is, IS) ---> S2 --- (Exciting, exciting, EXCITING) ---> S3
Language Model FSA
The language model FSA encodes a language model into a FSA structure. Two states are default for every LM FSA: start and eps states. Transitions from a state to another contain a word and the probability of the destination state ngram. Transitions from a state to the eps state contain the backoff probability of that ngram.
When initialized, the LanguageModelFSA object takes as parameters URL objects which contain the location of the language model, a dictionary and a filler dictionary. In this class I have used the sphinx4 library to read the language model. When created, the object outputs three files: a file which contains the fsa (lm_fsa), the input symbols table (lm_fsa_isyms) which is the same as the output symbols table (in case we want to consider a FST) and the state symbols table (lm_fsa_ssyms). If needed the output can be compiled with openfst and printed.
[caption id="" align="aligncenter" width="684" caption="Language Model FST"] [/caption]
[/caption]
To download the code: svn co https://cmusphinx.svn.sourceforge.net/svnroot/cmusphinx/branches/ppf
Compile with make and run program with scripts/createfsa.sh with the string you want to model into a FSA, the path to the LM, dictionary and filler dictionary as parameters.
Compatibility issues using binary fst models generated by OpenGrm NGram Library with phonetisaurus decoder
(author: John Salatas)
Foreword
Previous articles have shown how to use OpenGrm NGram Library for the encoding of joint multigram language models as WFST [1] and provided the code that simplifies and automates the fst model training [2]. As described in [1] the generated binary fst models with the procedures described in those articles are not directly usable from phonetisaurus [3] decoder.
This article will try to describe the compatibility issues in more details and provide some intuition on possible solutions and workarounds.
1. Open issues
Assuming a binary fst model, named cmudict.fst generated as described in [1], trying to evaluate it with phonetisaurus evaluate python script, results in the following error
$ ./evaluate.py --order 9 --modelfile cmudict.fst --testfile cmudict.dict.test.tabbed --prefix cmudict/cmudict
../phonetisaurus-g2p --model=cmudict.fst --input=cmudict/cmudict.words --beam=1500 --alpha=0.6500 --prec=0.8500 --ratio=0.7200 --order=9 --words --isfile > cmudict/cmudict.hyp
Symbol: 'A' not found in input symbols table.
Mapping to null...
Symbol: '4' not found in input symbols table.
Mapping to null...
Symbol: '2' not found in input symbols table.
Mapping to null...
Symbol: '1' not found in input symbols table.
Mapping to null...
Symbol: '2' not found in input symbols table.
Mapping to null...
Symbol: '8' not found in input symbols table.
Mapping to null...
sh: line 1: 18788 Segmentation fault ../phonetisaurus-g2p --model=cmudict.fst --input=cmudict/cmudict.words --beam=1500 --alpha=0.6500 --prec=0.8500 --ratio=0.7200 --order=9 --words --isfile > cmudict/cmudict.hyp
Words: 0 Hyps: 0 Refs: 13328
Traceback (most recent call last):
File "./evaluate.py", line 124, in
mbrdecode=args.mbrdecode, beam=args.beam, alpha=args.alpha, precision=args.precision, ratio=args.ratio, order=args.order
File "./evaluate.py", line 83, in evaluate_testset
PERcalculator.compute_PER_phonetisaurus( hypothesisfile, referencefile, verbose=verbose )
File "calculateER.py", line 333, in compute_PER_phonetisaurus
assert len(words)==len(hyps) and len(hyps)==len(refs)
AssertionError
2. Disussion on open issues
In order to investigate the error above, a simple aligned corpus was created as below
a}a b}b
a}a
a}a c}c
a}a b}b c}c
a}a c}c
b}b c}c
This simple corpus was used as input to both ngram and phonetisaurus model training procedures [1], [3] and the generated fst model (binary.fst) was visualized as follows
$ fstdraw binary.fst binary.dot
$ dot -Tps binary.dot > binary.ps
the generated two postscript outputs, using phonetisaurus and ngram respectively, are shown in the following figures:
[caption id="attachment_454" align="aligncenter" width="517" caption="Figure 1: Visualization of the fst model generated by phonetisaurus"]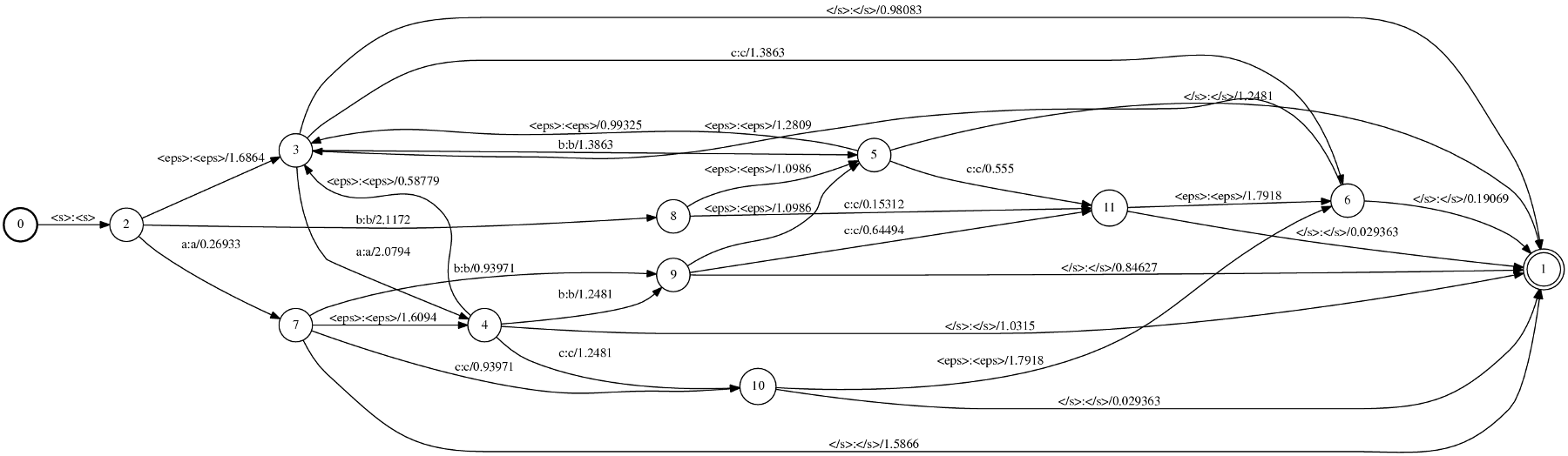 [/caption]
[/caption]
[caption id="attachment_459" align="aligncenter" width="517" caption="Figure 2: Visualization of the fst model generated by ngram"]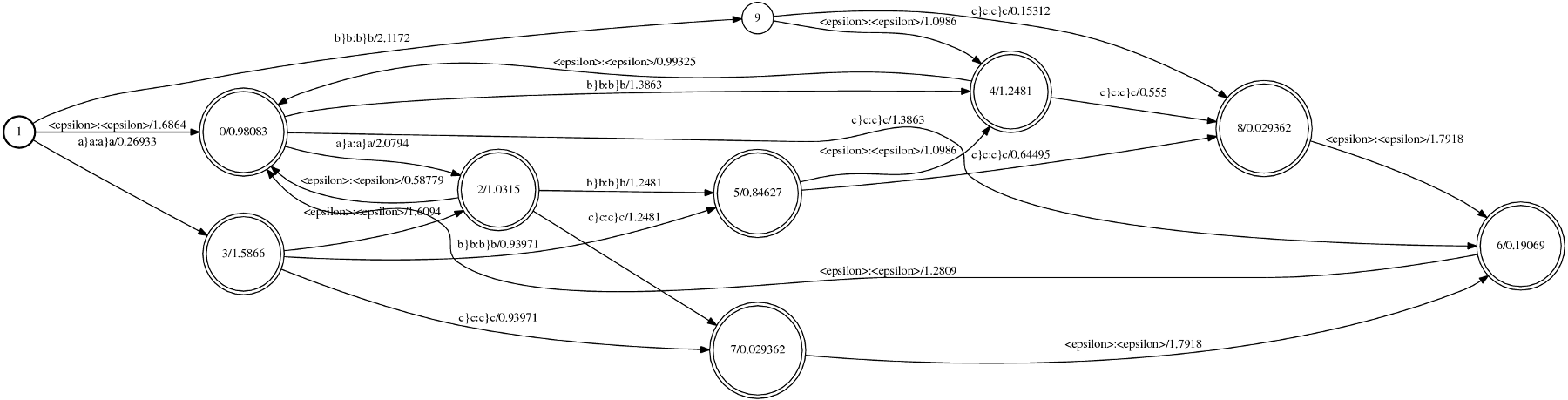 [/caption]
[/caption]
By studying the two figures above the first obvious conclusion is that the model generated with ngram do not distinguish between graphemes (input label) and phonemes (output label), but it uses the joint multigram (eg “a}a”) as both input and output label.
Another obvious difference between the two models is the starting and final state(s). Phonetisaurus models have a fixed starting state with a single outgoing arc with labels : labels in all incoming arcs. and no weight. Furthermore, in phonetisaurus model there exist only a single final state with :
3. Possible solutions and workarounds
[1] already presents a workaround to bypass the compatibility issues described in the previous section. We can simply export the ngram generated binary fst model to an ARPA format with:
$ ngramprint --ARPA binary.fst > export.arpa
and the use phonetisaurus' arpa2fst convert utility to regenerate a new binary fst model compatible with phonetisaurus' decoder.
$ phonetisaurus-arpa2fst –input=export.arpa
Although this is a straightforward procedure, a more elegant solution would be to iterate in all arcs and manually break apart the grapheme/phoneme joint multigram labels to input/output labels accordingly. A final step, if necessary, would be to add the start and single final state in the ngram generated fst model.
4. Conclusion – Future work
This article tried to provide some intuition on the compatibility issues between ngram and phonetisaurus models and also to possible solutions and workarounds. As explained in the previous section, there is already a straightforward procedure to overcome these issues (export to ARPA format and regenerate the binary model), but in any case it is worth to try the relabeling approach described also in the previous section.
References
[1] Using OpenGrm NGram Library for the encoding of joint multigram language models as WFST.
[2] Automating the creation of joint multigram language models as WFST.
[3] Phonetisaurus: A WFST-driven Phoneticizer – Framework Review