Pocketsphinx for Pronunication Evaluation
UPDATE: please see this paper for a far superior method developed during the 2017 Google Summer of Code superceding all of the below.
Caution!
This tutorial describes pocketsphinx 5 pre-alpha release. It is not up-to-date with the current development version and will be updated soon.
This is a short tutorial with references by James Salsman (jim at talknicer dot com.)
Installation and testing
First, on a system with the gcc C compiler toolchain, install automake, python including development libraries and swig, e.g. this way on Debian or Ubuntu:
sudo apt-get install automake python python-dev swig
Then you can install and test pocketsphinx this way:
svn checkout svn://svn.code.sf.net/p/cmusphinx/code/trunk/sphinxbase
cd sphinxbase
./autogen.sh
make
sudo make install
cd ..
svn checkout svn://svn.code.sf.net/p/cmusphinx/code/trunk/pocketsphinx
cd pocketsphinx
./autogen.sh
make
sudo make install
cd test/regression
./test-lm.sh
If you don’t have root privileges on the machine where you’re installing, you
can skip the sudo apt-get command and instead make a new local directory,
e.g. mkdir $HOME/pocketsphinx and then use ./autogen.sh --prefix=$HOME/pocketsphinx --without-python
for both of the autogen commands, and omit the sudo prefix when executing the two make install
commands. Executable binaries will be installed to the bin subdirectory, e.g.
~/pocketsphinx/bin/pocketsphinx_continuous
If you are on MacOSX, you will need to install autoconf, automake, and libtool first.
Configuration files
Then, create these files with which to test pronunciation assessment:
phonemes.dict - use a tab instead of spaces for each of the CMUBET:
aa AA
ae AE
ah AH
ao AO
aw AW
ay AY
b B
ch CH
d D
dh DH
eh EH
er ER
ey EY
f F
g G
hh HH
ih IH
iy IY
jh JH
k K
l L
m M
n N
ng NG
ow OW
oy OY
p P
r R
s S
sh SH
sil SIL
ss S
t T
th TH
uh UH
uw UW
v V
w W
y Y
z Z
zh ZH
words.dict - Again, the first whitespace on each line should be one tab; include SILence:
dance D AE N S
sil SIL
toy T OY
with W IH DH
Add as many more words from CMUDICT or make them up from the CMUBET as you need. Just make sure SIL is in there as “sil”.
Then make an audio recording of one of those words, such as “with,” spoken in a sound file called e.g. with.wav at 16,000 samples per second with 16 bits per sample and 1 monophonic channel.
Here are the JSGF format finite state grammar (FSG) files for pronunciation assessment of that single word “with”:
with-align.jsgf is for forced alignment of phonemes:
#JSGF V1.0;
grammar forcing;
public <with> = sil w ih dh [ sil ];
with-neighbors.jsgf identifies whether the expected phonemes are recognized as more or less likely to have been pronounced than their nearest covering physicologically neighboring phonemes as defined by incremental displacements of the vocal tract components:
#JSGF V1.0;
grammar neighbors;
public <with> = sil <w> <ih> <dh> [ sil ];
<aa> = aa | ah | er | ao;
<ae> = ae | eh | er | ah;
<ah> = ah | ae | er | aa;
<ao> = ao | aa | er | uh;
<aw> = aw | aa | uh | ow;
<ay> = ay | aa | iy | oy | ey;
<b> = b | p | d;
<ch> = ch | sh | jh | t;
<dh> = dh | th | z | v;
<d> = d | t | jh | g | b;
<eh> = eh | ih | er | ae;
<er> = er | eh | ah | ao;
<ey> = ey | eh | iy | ay;
<f> = f | hh | th | v;
<g> = g | k | d;
<hh> = hh | th | f | p | t | k;
<ih> = ih | iy | eh;
<iy> = iy | ih;
<jh> = jh | ch | zh | d;
<k> = k | g | t | hh;
<l> = l | r | w;
<m> = m | n;
<ng> = ng | n;
<n> = n | m | ng;
<ow> = ow | ao | uh | aw;
<oy> = oy | ao | iy | ay;
<p> = p | t | b | hh;
<r> = r | y | l;
<ss> = sh | s | z | th;
<sh> = sh | s | zh | ch;
<t> = t | ch | k | d | p | hh;
<th> = th | s | dh | f | hh;
<uh> = uh | ao | uw | uw;
<uw> = uw | uh | uw;
<v> = v | f | dh;
<w> = w | l | y;
<y> = y | w | r;
<z> = z | s | dh | z;
<zh> = zh | sh | z | jh;
Note that the production for the covering phonemes neighboring /S/ is coded as
<ss> to avoid ambiguity with the start token <s>, which is why /S/ is under
‘s’ and ‘ss’ in the phonemes.dict file above.
with-word.jsgf performs whole word alignment:
#JSGF V1.0;
grammar word;
public <wholeutt> = sil with [ sil ];
For multiple words use something like public <wholeutt> = sil dance [ sil ]
with [ sil ] toy [ sil ]; on the final line. Similarly for the phoneme files,
the public production should just include more phonemes with [ optional ]
sil-ence inserted between the adjacent words.
Running PocketSphinx
Then you can run these three different passes of speech recognition. Each below is a single command line with line breaks for clarity:
Forced alignment of phonemes
pocketsphinx_continuous
-infile with.wav
-jsgf with-align.jsgf
-dict phonemes.dict
-backtrace yes
-fsgusefiller no
-bestpath no
2>&1 > with-alignment.txt
Physiologically neighboring phoneme discrimination
pocketsphinx_continuous
-infile with.wav
-jsgf with-neighbors.jsgf
-dict phonemes.dict
-backtrace yes
-fsgusefiller no
-bestpath yes
2>&1 > with-neighbors.txt
Forced alignment of whole words
pocketsphinx_continuous
-infile with.wav
-jsgf with-word.jsgf
-dict words.dict
-backtrace yes
-fsgusefiller no
-bestpath no
2>&1 > with-word.txt
Output
The output should look roughly like this:
$ tail with-*.txt
==> with-alignment.txt <==
INFO: pocketsphinx.c(1171): sil w ih dh sil (-2822)
word start end pprob ascr lscr lback
sil 3 77 1.000 -1797 0 1
w 78 83 1.000 -377 0 1
ih 84 86 1.000 -147 0 1
dh 87 102 1.000 -335 0 1
sil 103 107 1.000 -166 0 1
INFO: fsg_search.c(265): TOTAL fsg 0.22 CPU 0.209 xRT
INFO: fsg_search.c(268): TOTAL fsg 0.06 wall 0.058 xRT
sil w ih dh sil
==> with-neighbors.txt <==
INFO: pocketsphinx.c(1171): sil y eh v (-2888)
word start end pprob ascr lscr lback
sil 3 60 1.000 -1643 0 1
y 61 67 1.000 -352 0 1
eh 68 75 1.000 -332 0 1
v 76 107 1.000 -561 0 1
(NULL) 107 107 1.000 0 0 1
INFO: fsg_search.c(265): TOTAL fsg 0.68 CPU 0.644 xRT
INFO: fsg_search.c(268): TOTAL fsg 0.69 wall 0.657 xRT
sil y eh v
==> with-word.txt <==
INFO: fsg_search.c(869): fsg 0.05 CPU 0.051 xRT
INFO: fsg_search.c(871): fsg 0.09 wall 0.084 xRT
INFO: pocketsphinx.c(1171): sil with sil (-2607)
word start end pprob ascr lscr lback
sil 3 77 1.000 -1602 0 1
with 78 102 1.000 -845 0 1
sil 103 107 1.000 -160 0 1
INFO: fsg_search.c(265): TOTAL fsg 0.05 CPU 0.051 xRT
INFO: fsg_search.c(268): TOTAL fsg 0.09 wall 0.085 xRT
sil with sil
Here, the start and end columns are in hundredths of a second, the acoustic score “ascr” is the only other meaningful column, and the rows are phonemes – the first set is the “forced alignment” of the expected phonemes, the second set of rows are the phonemes physiologically neighboring the expected phonemes which best matched the kid’s speech utterance, and the third set of rows has the acoustic score for the whole word.
Note that acoustic scores are given in log-probabilities, so they are negative
numbers, with larger numbers (e.g. negative numbers closer to zero)
corresponding to greater confidence that the phoneme or word was pronounced
when -bestpath no is used.
Make sure you use -bestpath no on zero perplexity phoneme alignment and
word alignment FSGs, but -bestpath yes on the higher perplexity neighboring
phoneme grammar, and do not depend on the resulting acoustic scores from those
high perplexity FSGs because they do not correlate to confidence.
Often, mispronunciations and ordinary background noise will result in missing
scores, superfluous entries in the backtrace tables (e.g. “(NULL)” as
above), multiple output tables per invocation, and other confounding factors,
all of which you will need to experiment with to be able to successfully parse
the output.
Performing pronunciation assessment
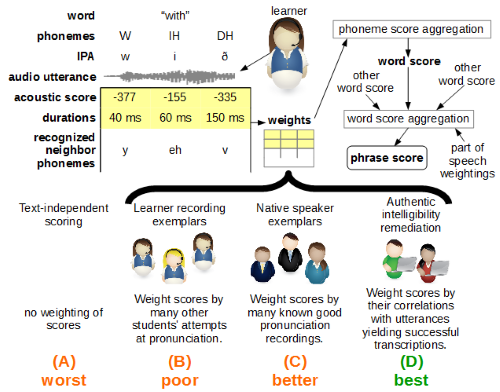
You can use logistic regression, for example to predict the percentage of transcriptionists who were able to successfully type the word “with” after listening to the audio with.wav file, using as independent variables:
-
the acoustic score of each phoneme in each word,
-
the duration of each phoneme in each word,
-
the phoneme recognized in place of each expected phoneme, and
-
the acoustic score of the entire word.
Consider taking the log of 1 minus the acoustic scores (which should be in a lognormal distribution in their negative integer form, for both aligned phonemes and whole words) so that they form a normal distribution, and then converting them to standard scores (standard deviations above the mean of the normal distribution.) Durations are also likely to start out as almost a lognormal distribution (being non-negative, but zero for some mispronounced phonemes) and you can do the same for them, adding instead of subtracting from 1. When converting to standard scores, be sure to use the mean and standard deviation of the log(1-ascr) and log(1+duration) populations from each phoneme separately. You can not compare the acoustic score or duration of different phonemes in different words or different positions in the same word, even if they are from the same phoneme. You can’t even reliably compare the scores and durations of the same phoneme from identical words in different contexts.
How best to use the non-quantitative neighboring phoneme data is an exciting
open question in machine learning. Please don’t use the acoustic scores from
-bestpath yes neighboring phoneme finite state grammars, but you might want
to experiment with -bestpath no scores from such grammars when their output
is locally similar (same previous, current, and subsequent phonemes) to that of
the -bestpath yes results. Please share what you learn.
Examples
Note: These examples make heavy use of the AWK programming language (man page; GNU awk manual) along with various bash shell and associated unix commands.
The file wyn.tar.gz has the .wav audio, script, and data files below. It’s based on 80 audio utterances named wyn01.wav through wyn80.wav of students asked to pronounce the words “What’s your name?” with varying degrees of success, from silence through intelligible pronunciation. The utterances are scored using these commands:
$ for w in wyn*.wav ; do pocketsphinx_continuous -infile $w -jsgf wyn-align.jsgf -dict phonemes.dict -backtrace yes -fsgusefiller no -bestpath no 2>&1 | tee $w-align.txt ; done
$ for w in wyn*.wav ; do pocketsphinx_continuous -infile $w -jsgf wyn-neighbors.jsgf -dict phonemes.dict -backtrace yes -fsgusefiller no -bestpath yes 2>&1 | tee $w-neighbors.txt ; done
$ for w in wyn*.wav ; do pocketsphinx_continuous -infile $w -jsgf wyn-words.jsgf -dict words.dict -backtrace yes -fsgusefiller no -bestpath no 2>&1 | tee $w-words.txt ; done
Phoneme acoustic scores and durations
This results in creating the 240 text output files wynNN.wav-align.txt, wynNN.wav-neighbors.txt, and wynNN.wav-words.txt with the output of each command. We will work with the acoustic scores and durations in the -align.txt files. The following command will extract the acoustic scores (negative integers) durations (in seconds with two hundredths digits of precision) in that order:
$ for f in *-align.txt ; do awk '/^(w|ah|t|s|y|uh|r|n|ey|m) / {printf "%2s %5d %4.2f ", $1, $5, ($3-$2)/100.0} END {print FILENAME}' $f >> alignments.txt ; done
The output file produced by that command looks like this:
$ head alignments.txt
w -208 0.02 ah -141 0.02 t -76 0.03 s -175 0.03 y -183 0.09 uh -151 0.02 r -77 0.06 n -146 0.03 ey -487 0.37 m -134 0.08 wyn01.wav-align.txt
w -89 0.05 ah -62 0.03 t -390 0.18 s -447 0.02 y -217 0.04 uh -109 0.02 r -154 0.02 n -208 0.02 ey -267 0.18 m -90 0.04 wyn02.wav-align.txt
w -364 0.14 ah -271 0.03 t -111 0.05 s -210 0.02 y -99 0.05 uh -100 0.03 r -111 0.03 n -262 0.06 ey -304 0.08 m -213 0.03 wyn03.wav-align.txt
w -1148 0.27 ah -693 0.20 t -279 0.02 s -637 0.02 y -99 0.05 uh -80 0.03 r -176 0.07 n -276 0.04 ey -334 0.14 m -287 0.11 wyn04.wav-align.txt
w -68 0.06 ah -170 0.06 t -137 0.06 s -78 0.02 y -199 0.02 uh -105 0.04 r -180 0.02 n -171 0.04 ey -976 0.36 m -255 0.13 wyn05.wav-align.txt
wyn06.wav-align.txt
wyn07.wav-align.txt
wyn08.wav-align.txt
w -279 0.02 ah -149 0.02 t -621 0.29 s -406 0.11 y -195 0.02 uh -274 0.05 r -151 0.05 n -837 0.25 ey -676 0.12 m -158 0.05 wyn09.wav-align.txt
wyn10.wav-align.txt
....`
Some of the files have no data as shown, some of them for good reasons and others for unknown reasons possibly related to a lack of silence at the beginning of the audio file. We can convert this lognormally-distributed data to a more normal distribution by using natural log functions thusly:
$ for f in *-align.txt ; do awk '/^(w|ah|t|s|y|uh|r|n|ey|m) / {printf "%2s %6.3f %6.3f ", $1, -log(1-$5), log($3-$2+1)} END {print FILENAME}' $f | tee -a normalign.txt ; done
The output file from that command looks like this:
$ head normalign.txt
w -5.342 1.099 ah -4.956 1.099 t -4.344 1.386 s -5.170 1.386 y -5.215 2.303 uh -5.024 1.099 r -4.357 1.946 n -4.990 1.386 ey -6.190 3.638 m -4.905 2.197 wyn01.wav-align.txt
w -4.500 1.792 ah -4.143 1.386 t -5.969 2.944 s -6.105 1.099 y -5.384 1.609 uh -4.700 1.099 r -5.043 1.099 n -5.342 1.099 ey -5.591 2.944 m -4.511 1.609 wyn02.wav-align.txt
w -5.900 2.708 ah -5.606 1.386 t -4.718 1.792 s -5.352 1.099 y -4.605 1.792 uh -4.615 1.386 r -4.718 1.386 n -5.572 1.946 ey -5.720 2.197 m -5.366 1.386 wyn03.wav-align.txt
w -7.047 3.332 ah -6.542 3.045 t -5.635 1.099 s -6.458 1.099 y -4.605 1.792 uh -4.394 1.386 r -5.176 2.079 n -5.624 1.609 ey -5.814 2.708 m -5.663 2.485 wyn04.wav-align.txt
w -4.234 1.946 ah -5.142 1.946 t -4.927 1.946 s -4.369 1.099 y -5.298 1.099 uh -4.663 1.609 r -5.198 1.099 n -5.147 1.609 ey -6.884 3.611 m -5.545 2.639 wyn05.wav-align.txt
wyn06.wav-align.txt
wyn07.wav-align.txt
wyn08.wav-align.txt
w -5.635 1.099 ah -5.011 1.099 t -6.433 3.401 s -6.009 2.485 y -5.278 1.099 uh -5.617 1.792 r -5.024 1.792 n -6.731 3.258 ey -6.518 2.565 m -5.069 1.792 wyn09.wav-align.txt
wyn10.wav-align.txt
....
We can use the lines in that file with good data (and therefore a space) to produce means and standard deviations, and thereby standard scores, like this:
grep ' ' normalign.txt | awk '{if (!mnf || NF<mnf) {mnf=NF}; for (f=1; f<NF; f++) {i[NR,f]=$f; if ((f-1) % 3) {m[f]+=$f; d[f]=$f-a[f]; a[f]+=d[f]/NR; m2[f]+=d[f]*($f-a[f])}}; i[NR,0]=$NF} END {print "Means and standard deviations of acoustic scores and durations for each phoneme:"; for (f=1; f<mnf; f++) {if ((f-1) % 3) {printf "%5.3f %5.3f ", m[f]/NR, sqrt(m2[f]/NR)} else {printf "%s ", $f}}; print "\n\nStandard scores of acoustic scores and durations for each scored utterance:"; for (r=1; r<=NR; r++) {for (f=1; f<mnf; f++) {if ((f-1) % 3) {printf "%+6.3f ", (i[r,f]-(m[f]/NR))/sqrt(m2[f]/NR)} else {printf "%s ", i[r,f]}}; print i[r,0]}}' > standards.txt
The output of that lengthy AWK command produces means, standard deviations, and standard scores:
$ head standards.txt
Means and standard deviations of acoustic scores and durations for each phoneme:
w -4.987 0.776 2.204 0.594 ah -4.921 0.706 1.714 0.543 t -5.224 0.654 1.916 0.682 s -5.078 0.545 1.657 0.534 y -5.145 0.496 1.525 0.498 uh -4.930 0.461 1.593 0.505 r -5.201 0.604 1.802 0.785 n -5.466 0.487 1.927 0.598 ey -5.674 0.452 2.583 0.717 m -5.475 0.561 2.303 0.816
Standard scores of acoustic scores and durations for each scored utterance:
w -0.458 -1.858 ah -0.050 -1.133 t +1.346 -0.777 s -0.170 -0.508 y -0.141 +1.563 uh -0.203 -0.979 r +1.396 +0.184 n +0.978 -0.905 ey -1.141 +1.471 m +1.016 -0.131 wyn01.wav-align.txt
w +0.627 -0.692 ah +1.102 -0.605 t -1.139 +1.508 s -1.885 -1.045 y -0.482 +0.169 uh +0.499 -0.979 r +0.261 -0.895 n +0.254 -1.384 ey +0.183 +0.503 m +1.719 -0.851 wyn02.wav-align.txt
w -1.177 +0.848 ah -0.971 -0.605 t +0.774 -0.182 s -0.503 -1.045 y +1.090 +0.536 uh +0.683 -0.411 r +0.798 -0.529 n -0.218 +0.031 ey -0.102 -0.539 m +0.194 -1.125 wyn03.wav-align.txt
w -2.656 +1.898 ah -2.297 +2.450 t -0.628 -1.198 s -2.533 -1.045 y +1.090 +0.536 uh +1.162 -0.411 r +0.041 +0.353 n -0.325 -0.532 ey -0.310 +0.174 m -0.336 +0.222 wyn04.wav-align.txt
w +0.970 -0.433 ah -0.313 +0.426 t +0.454 +0.044 s +1.300 -1.045 y -0.308 -0.857 uh +0.579 +0.031 r +0.004 -0.895 n +0.655 -0.532 ey -2.675 +1.434 m -0.126 +0.411 wyn05.wav-align.txt
w -0.836 -1.858 ah -0.128 -1.133 t -1.849 +2.178 s -1.709 +1.550 y -0.268 -0.857 uh -1.489 +0.393 r +0.292 -0.012 n -2.600 +2.224 ey -1.866 -0.025 m +0.723 -0.627 wyn09.wav-align.txt
....
Here is a graphical depiction of all that data:
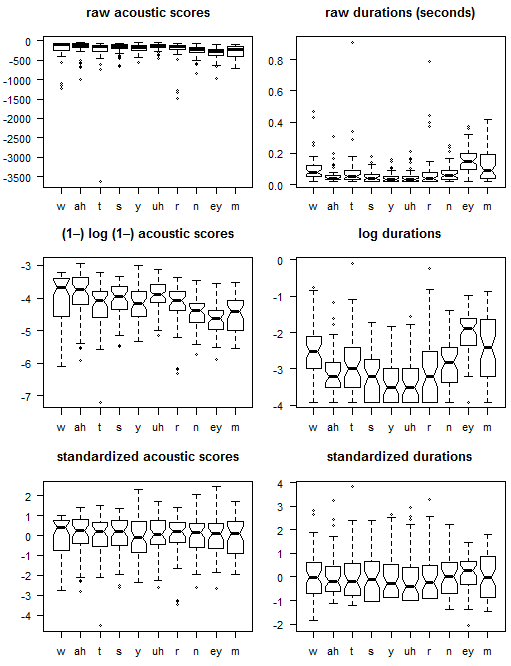
The standard scores are suitable for aggregation with simple arithmetic means, and can be used along with the neighboring phoneme symbols (from the -neighbors.txt files) and word scores for logistic regression to predict whether correct human transcriptions can be obtained from the audio utterance, or for support vector machine (SVM) and neural network alternatives to logistic regression.
You can hear that simply averaging each phrase’s standardized acoustic scores is a useful approximate measure of intelligibility, because the three highest scoring utterances, wyn21.wav, wyn26.wav, and wyn39.wav, are all clearly intelligible, while the lowest scoring wyn09.wav omitted the entire first word, possibly due to a slow microphone, wyn43.wav is attenuated with loud breath static, and wyn04.wav is a completely wrong phrase.
Physiologically neighboring phonemes
We can study the expected and nearest covering physiologically neighboring phonemes which were recognized from the student utterances this way:
$ awk '/^word / {if (nl) {print ""}; printf FILENAME " "; nl=1; next} / / && !/^sil / && !/NULL/ {printf $1 " "} END {print ""}' wyn*.wav-neighbors.txt > neighbors.txt
$ head neighbors.txt
wyn01.wav-neighbors.txt l ah t s y ao r n ey m
wyn02.wav-neighbors.txt w ah t sh r uh y n ay n
wyn03.wav-neighbors.txt l ah d th y uw l m ay n
wyn04.wav-neighbors.txt w aa p th w uh y ng iy n
wyn05.wav-neighbors.txt w ah t sh r uw y n ey m
wyn08.wav-neighbors.txt w aa p sh y ao l n ey n
wyn09.wav-neighbors.txt l ae t th y uw r n ey n
wyn13.wav-neighbors.txt w er t th w ao y n iy n
wyn14.wav-neighbors.txt w er p th w uw l ng ay m
wyn16.wav-neighbors.txt l ah t sh y ao y n eh n
....
71 of the 80 files produced such results. Let’s count how many most closely matched the expected phonemes in each utterance:
$ awk '{print ($2=="w")+($3=="ah")+($4=="t")+($5=="s")+($6="y")+($7=="uh")+($8=="r")+($9=="n")+($10=="ey")+($11=="m"), $1}' neighbors.txt | sort -n
0 wyn61.wav-neighbors.txt
1 wyn03.wav-neighbors.txt
1 wyn54.wav-neighbors.txt
1 wyn80.wav-neighbors.txt
2 wyn04.wav-neighbors.txt
2 wyn14.wav-neighbors.txt
...
7 wyn48.wav-neighbors.txt
7 wyn51.wav-neighbors.txt
7 wyn53.wav-neighbors.txt
8 wyn29.wav-neighbors.txt
This method is also easily validated by ear, as wyn61.wav is not just poor pronunciation, but a different word entirely from the expected phrase, and wyn29.wav is clearly intelligible. An ideal pronunciation assessment would at least combine information from the acoustic scores, relative durations, and the closest matching neighboring phonemes.
Rank correlations of these methods
All of the methods shown above have positive rank correlations with each other and the overall phrase acoustic scores in the -words.txt word-level alignments which are not shown above.
| Kendall’s tau non-parametric rank correlation | A | N | P | W |
|---|---|---|---|---|
| A: acoustic score of entire phoneme alignment | 1 | 0.44 | 0.74 | 0.85 |
| N: number of expected phonemes among neighbors | 0.44 | 1 | 0.57 | 0.47 |
| P: mean standardized phoneme acoustic scores | 0.74 | 0.57 | 1 | 0.71 |
| W: acoustic score of word alignment (not shown) | 0.85 | 0.47 | 0.71 | 1 |
The overall phrase acoustic scores are shown in parentheses at the end of these lines in the pocketsphinx output:
wyn20.wav-align.txt:INFO: pocketsphinx.c(1171): sil w ah t s y uh r n ey m sil (-4099)
wyn20.wav-words.txt:INFO: pocketsphinx.c(1171): sil whats your name sil (-4393)
The extent to which each of these methods correlate with intelligibility or good pronunciation is left as an exercise. Note that all these ranking methods are only using comparisons to other students (method (B) “poor” in the diagram above) so they are far inferior to the authentic intelligibility remediation method described in the Loukina et al. (2015) and Kibishi et al. (2014) in the References below.
Troubleshooting
If you encounter the “Final result does not match the grammar” error, first,
check to see that you’re using <ss> instead of the start symbol <s> in the
neighbor phoneme recognition JSGF files. If that’s not the problem, try making
the -wbeam and/or -beam parameters smaller (smaller values mean a wider
search beam.)
-
-wbeam (default 7e-29) Beam width applied to word exits (isolated phonemes in this case): Try 1e-56
-
-beam (default 1e-48) Beam width applied to every frame in Viterbi search: Try 1e-57
I.e., try -wbeam 1e-56 -beam 1e-57 on the pocketsphinx_continious
command lines. Thanks to Pavel Denisov for those values. These are specified in
base-10 exponent scientific notation, but they will be reported by pocketsphinx
as negative integer logarithm probability state transition pruning thresholds
thusly:
INFO: fsg_search.c(227): FSG(beam: -1282, pbeam: -1080, wbeam: -1260; wip: -26, pip: 0)
Here is the beginnings of an optimization task for setting those and other command line search parameters. Here is a paper describing a different approach to obtaining difficult alignments of longer utterances. Please see also: http://cmusphinx.github.io/2014/07/long-audio-aligner-landed-in-trunk/
Remember that PocketSphinx has an API because you have the source code and you can modify it to do what you want it to do, so you can program it in C which is much faster than bash and AWK.
PocketSphinx.js
Two prospective student applicants (so far) for the 2017 Google Summer of Code ported the “What’s your name” examples above to pocketsphinx.js:
Those require Chrome or Firefox with WebRTC (GetUserMedia) microphone audio input permission.
References
Loukina, et al. (September 2015) “Pronunciation accuracy and intelligibility of non-native speech,” in InterSpeech-2015, the Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association (Dresden, Germany: Educational Testing Service.) http://www.oeft.com/su/pdf/interspeech2015b.pdf
Kibishi, et al. (May 2014) “A statistical method of evaluating the pronunciation proficiency/intelligibility of English presentations by Japanese speakers,” ReCALL (European Association for Computer Assisted Language Learning.) doi:10.1017/S0958344014000251. http://www.slp.ics.tut.ac.jp/Material_for_Our_Studies/Papers/shiryou_last/e2014-Paper-01.pdf
Ronanki, Salsman, and Bo (December 2012) “Automatic Pronunciation Evaluation And Mispronunciation Detection Using CMUSphinx,” in the Proceedings of the 24th International Conference on Computational Linguistics (Mumbai, India: COLING 2012) pp. 61-67: http://www.aclweb.org/anthology/W12-5808 Source code repository: https://sourceforge.net/p/cmusphinx/code/HEAD/tree/branches/speecheval/ Blog: http://pronunciationeval.blogspot.com/
Salsman, J. (July 2014) “Development challenges in automatic speech recognition for computer assisted pronunciation teaching and language learning” in Proceedings of the Research Challenges in Computer Aided Language Learning Conference (Antwerp, Belgium: CALL 2014.) http://talknicer.com/Salsman-CALL-2014.pdf
CMUSphinx PocketSphinx tutorial: https://cmusphinx.github.io/wiki/tutorialpocketsphinx
Huggins-Daines, David, et al. (2006) “Pocketsphinx: A free, real-time continuous speech recognition system for hand-held devices.” Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) vol. 1: https://www.cs.cmu.edu/~awb/papers/ICASSP2006/0100185.pdf
PocketSphinx source code: https://cmusphinx.github.io/doc/pocketsphinx/files.html
Russell et al. (November 1992) “Children’s speech training aid,” U.S. Patent 5,679,001 (expired; originally issued in U.K. as “Speech training aid.”) https://www.google.com/patents/US5679001
Proceedings of the International Symposium on Automatic Detection of Errors in Pronunciation Training, June 6–8, 2012, KTH, Stockholm, Sweden. http://www.speech.kth.se/isadept/ISADEPT-proceedings.pdf
Proceedings of the Workshop on Speech and Language Technology in Education, September 4–5, 2015 (Satellite Workshop of Interspeech 2015 and the ISCA Special Interest Group SLaTE) Leipzig, Germany. https://www.slate2015.org/files/SLaTE2015-Proceedings.pdf
Chen and Li (2016) “Computer-assisted pronunciation training: From pronunciation scoring towards spoken language learning” Proceedings of the 2016 Asian-Pacific Signal and Information Processing Association (APSIPA) Annual Summit and Conference: http://www.apsipa.org/proceedings_2016/HTML/paper2016/227.pdf
Computer-Assisted Pronunciation Teaching Bibliography: http://liceu.uab.es/~joaquim/applied_linguistics/L2_phonetics/CALL_Pron_Bib.html
Panayotov, V., et al. (2015) “LIBRISPEECH: An ASR Corpus Based on Public Domain Audio Books” http://www.danielpovey.com/files/2015_icassp_librispeech.pdf
Hui Jiang (2005) “Confidence measures for speech recognition: A survey,” Speech Communication 45:455–470
Draft GSoC 2017 proposal
Please see https://en.wiktionary.org/wiki/Wiktionary:Grease_pit/2017/March#Please_comment_on_adding_pronunciation_assessment for a mocked-up example.
Goals
a. Eliminate all pronunciation assessment feedback which does not involve a consequential mispronunciation interfering with the student’s authentic intelligibility.
b. Transition mispronunciation feedback from visual signals to a pair of audio words in the learners’ first language, the first containing the correct phoneme and the second containing the mistaken sound produced.
c. Measure the resulting increased instructional productivity.
Phase I
Start collecting transcriptions of learner utterances. This data collection task is a bottleneck without which you can’t figure out which mispronunciations are consequential. So, for advanced learners, play another learner’s recording of a basic phrase recorded utterance, and simply ask them to type what they heard. For example, while displaying, “Please listen to this phrase and type in the English words you hear,” play this audio for the phrase: “I’m here on behalf of the Excellence Hotel group.” For this example, let’s say that in the audio, “behalf” was mispronounced as “beh-alf” and “Excellence” was mispronounced as “Excellent” but everything else was good.
The learner types in the text: “I’m here on behalf of the excellent hotel group.” (I.e., the transcribing advanced learner gets “behalf” right, but doesn’t transcribe Excellence correctly because it was mispronounced.)
The system sees that “Excellence” was not transcribed correctly, while the SR system reports two mispronunciations. Therefore, update the database entry for this phrase that a tally for the corresponding phonemes in “behalf” are inconsequential, but the final /s/ in “excellence” is consequential if mispronounced.
Phase II
After sufficient data is collected, start ignoring the inconsequential mispronunciations. This should be clear from above. Your database of all the phrases will have a probability associated with each phoneme. Scale each mispronunciation’s acoustic score with that probability to establish the cut-of point for the scaled values which will not be scored as wrong (or yellow instead of orange, e.g.)
Phase III
Create a library for words in each learner first language containing each phoneme near the front. This is not a particularly lengthy task compared to the coding involved to support it, but obviously it requires people fluent in all of the first languages. So, instead of showing green/yellow/orange you can play an e.g. Spanish word which has starts with a /s/ sound.
So, then you can say, in Spanish audio (it’s important to have this in first language audio): “When you said excellence [that target word in English] you needed the sound that [some Spanish word starting with /s/] starts with, but instead you pronounced the sound [some Spanish word starting with /t/] starts with. Listen to what you said… [play the learner’s mispronounced word.] You were supposed to say excellence [word in English again]. Click replay to hear this again.” All while displaying the word “Excellence” and two buttons, Replay and Continue.
Software component requirement checklist
-
Display phrases and collect recording (this needs to begin well in advance, along with the transcription collection)
-
Compare typed transcription to expected text
-
Ascertain per-phoneme results (as per e.g. speech recognition results from the 2012 GSoC work)
-
Store positive and negative tally counts into { phrases x phonemes } database for mispronunciation consequence
-
Ignore mispronunciations not meeting the calculated threshold
-
Display unintelligibly mispronounced word
-
Lookup first language words corresponding to mispronunciations
-
Extract learner’s mispronounced word with segment time codes
-
Play recorded audio from extracted learner’s word(s)
-
Play recorded audio from first language word library