Hyperstring and Language Model FSA
(author: Alexandru Tomescu)
Foreword
As part of the PostProcessing Framework task of capitalization and punctuation recovery I am using Finite State Automata (FSA) to model hyperstrings ( all written forms of a text) and Language Models. These will be composed and a best-path search in the resulting FSA will output the best version (capitalized and punctuated) of a string.
Hyperstring FSA
The hyperstring FSA is composed from a string (i.e. "This is exciting") and considers all the possible written forms of the string.
S0 --- (This, this, THIS) ---> T0 --- (
, , ) ---> S1 --- (Is, is, IS) ---> T1 --- ( , , ) ---> S2 --- (Exciting, exciting, EXCITING) ---> T2 --- ( , , ) ---> S3
[caption id="" align="aligncenter" width="612" caption="Hyperstring FST"] [/caption]
[/caption]
S0 is the start state and S3 is the final state. Transitions between Si and Ti contain words and transitions between Ti and Ti+1 contain punctuation marks.
In the project this is represented by the FSA object which is constructed with the String we want to model and a boolean value which states if we also want punctuation added between transitions. If not the FSA will look like this:
S0 --- (This, this, THIS) ---> S1 --- (Is, is, IS) ---> S2 --- (Exciting, exciting, EXCITING) ---> S3
Language Model FSA
The language model FSA encodes a language model into a FSA structure. Two states are default for every LM FSA: start and eps states. Transitions from a state to another contain a word and the probability of the destination state ngram. Transitions from a state to the eps state contain the backoff probability of that ngram.
When initialized, the LanguageModelFSA object takes as parameters URL objects which contain the location of the language model, a dictionary and a filler dictionary. In this class I have used the sphinx4 library to read the language model. When created, the object outputs three files: a file which contains the fsa (lm_fsa), the input symbols table (lm_fsa_isyms) which is the same as the output symbols table (in case we want to consider a FST) and the state symbols table (lm_fsa_ssyms). If needed the output can be compiled with openfst and printed.
[caption id="" align="aligncenter" width="684" caption="Language Model FST"] [/caption]
[/caption]
To download the code: svn co https://cmusphinx.svn.sourceforge.net/svnroot/cmusphinx/branches/ppf
Compile with make and run program with scripts/createfsa.sh with the string you want to model into a FSA, the path to the LM, dictionary and filler dictionary as parameters.
Compatibility issues using binary fst models generated by OpenGrm NGram Library with phonetisaurus decoder
(author: John Salatas)
Foreword
Previous articles have shown how to use OpenGrm NGram Library for the encoding of joint multigram language models as WFST [1] and provided the code that simplifies and automates the fst model training [2]. As described in [1] the generated binary fst models with the procedures described in those articles are not directly usable from phonetisaurus [3] decoder.
This article will try to describe the compatibility issues in more details and provide some intuition on possible solutions and workarounds.
1. Open issues
Assuming a binary fst model, named cmudict.fst generated as described in [1], trying to evaluate it with phonetisaurus evaluate python script, results in the following error
$ ./evaluate.py --order 9 --modelfile cmudict.fst --testfile cmudict.dict.test.tabbed --prefix cmudict/cmudict
../phonetisaurus-g2p --model=cmudict.fst --input=cmudict/cmudict.words --beam=1500 --alpha=0.6500 --prec=0.8500 --ratio=0.7200 --order=9 --words --isfile > cmudict/cmudict.hyp
Symbol: 'A' not found in input symbols table.
Mapping to null...
Symbol: '4' not found in input symbols table.
Mapping to null...
Symbol: '2' not found in input symbols table.
Mapping to null...
Symbol: '1' not found in input symbols table.
Mapping to null...
Symbol: '2' not found in input symbols table.
Mapping to null...
Symbol: '8' not found in input symbols table.
Mapping to null...
sh: line 1: 18788 Segmentation fault ../phonetisaurus-g2p --model=cmudict.fst --input=cmudict/cmudict.words --beam=1500 --alpha=0.6500 --prec=0.8500 --ratio=0.7200 --order=9 --words --isfile > cmudict/cmudict.hyp
Words: 0 Hyps: 0 Refs: 13328
Traceback (most recent call last):
File "./evaluate.py", line 124, in
mbrdecode=args.mbrdecode, beam=args.beam, alpha=args.alpha, precision=args.precision, ratio=args.ratio, order=args.order
File "./evaluate.py", line 83, in evaluate_testset
PERcalculator.compute_PER_phonetisaurus( hypothesisfile, referencefile, verbose=verbose )
File "calculateER.py", line 333, in compute_PER_phonetisaurus
assert len(words)==len(hyps) and len(hyps)==len(refs)
AssertionError
2. Disussion on open issues
In order to investigate the error above, a simple aligned corpus was created as below
a}a b}b
a}a
a}a c}c
a}a b}b c}c
a}a c}c
b}b c}c
This simple corpus was used as input to both ngram and phonetisaurus model training procedures [1], [3] and the generated fst model (binary.fst) was visualized as follows
$ fstdraw binary.fst binary.dot
$ dot -Tps binary.dot > binary.ps
the generated two postscript outputs, using phonetisaurus and ngram respectively, are shown in the following figures:
[caption id="attachment_454" align="aligncenter" width="517" caption="Figure 1: Visualization of the fst model generated by phonetisaurus"]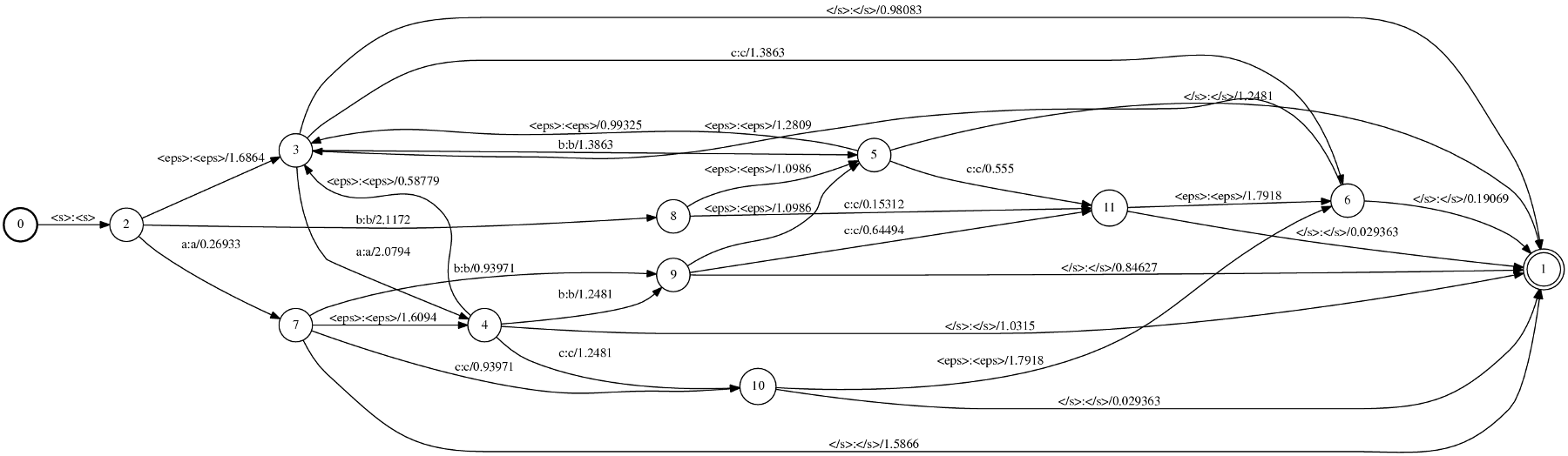 [/caption]
[/caption]
[caption id="attachment_459" align="aligncenter" width="517" caption="Figure 2: Visualization of the fst model generated by ngram"]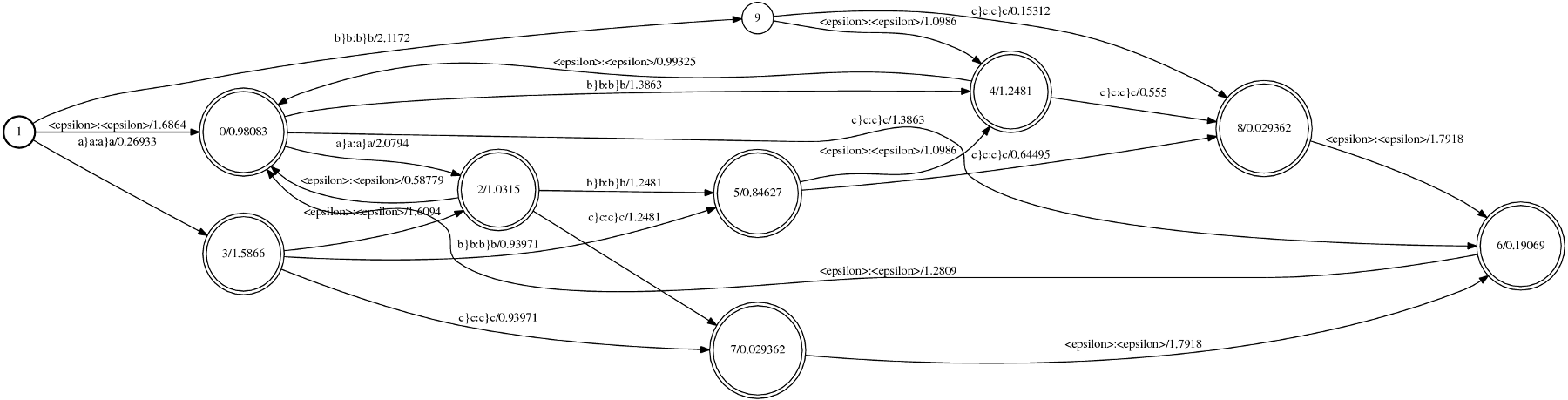 [/caption]
[/caption]
By studying the two figures above the first obvious conclusion is that the model generated with ngram do not distinguish between graphemes (input label) and phonemes (output label), but it uses the joint multigram (eg “a}a”) as both input and output label.
Another obvious difference between the two models is the starting and final state(s). Phonetisaurus models have a fixed starting state with a single outgoing arc with labels : labels in all incoming arcs. and no weight. Furthermore, in phonetisaurus model there exist only a single final state with :
3. Possible solutions and workarounds
[1] already presents a workaround to bypass the compatibility issues described in the previous section. We can simply export the ngram generated binary fst model to an ARPA format with:
$ ngramprint --ARPA binary.fst > export.arpa
and the use phonetisaurus' arpa2fst convert utility to regenerate a new binary fst model compatible with phonetisaurus' decoder.
$ phonetisaurus-arpa2fst –input=export.arpa
Although this is a straightforward procedure, a more elegant solution would be to iterate in all arcs and manually break apart the grapheme/phoneme joint multigram labels to input/output labels accordingly. A final step, if necessary, would be to add the start and single final state in the ngram generated fst model.
4. Conclusion – Future work
This article tried to provide some intuition on the compatibility issues between ngram and phonetisaurus models and also to possible solutions and workarounds. As explained in the previous section, there is already a straightforward procedure to overcome these issues (export to ARPA format and regenerate the binary model), but in any case it is worth to try the relabeling approach described also in the previous section.
References
[1] Using OpenGrm NGram Library for the encoding of joint multigram language models as WFST.
[2] Automating the creation of joint multigram language models as WFST.
[3] Phonetisaurus: A WFST-driven Phoneticizer – Framework Review
edit-distance grammar decoding using sphinx3: Part 1
(Author: Srikanth Ronanki)
(Status: GSoC 2012 Pronunciation Evaluation Week 3)
I finally finished trying different methods for edit-distance grammar decoding. Here is what I have tried so far:
1. I used sox to split each input wave file into individual phonemes based on the forced alignment output. Then, I tried decoding each phoneme against its neighboring phonemes. The decoding output matched the expected phonemes only 12 out of 41 times for the exemplar recordings in the phrase "Approach the teaching of pronunciation with more confidence"
The accuracy for that method of edit distance scoring was 12/41 (29%) -- This naive approach didn't work well.
2. I used sox to split each input wave file into three phonemes based on the forced alignment output and position of the phoneme. If a phoneme is at beginning of its word, I used a grammar like: (current phone) (next) (next2next) and if it is middle phoneme: (previous) (current) (next) and if it is at the end: (previous2previous) (previous) (current) and supplied neighboring phones for the current phone and fixed the other two.
For example, phoneme IH in word "with" is encoded as:
((W) (IH|IY|AX|EH) (TH))
The accuracy was 19/41 (46.2%) -- better because of more contextual information.
3. I used the entire phrase with each phoneme encoded in a sphinx3_decode grammar file for matching a sequence of alternative neighboring phonemes which looks something like this:
#JSGF V1.0;
grammar phonelist;
public
= (SIL (AH|AE|ER|AA) (P|T|B|HH) (R|Y|L) (OW|AO|UH|AW) (CH|SH|JH|T) (DH|TH|Z|V)(AH|AE|ER|AA) (T|CH|K|D|P|HH) (IY|IH|IX) (CH|SH|JH|T) (IH|IY|AX|EH) (NG|N) (AH|AE|ER|AA) (V|F|DH) (P|T|B|HH)(R|Y|L) (AH|AE|ER|AA) (N|M|NG) (AH|AE|ER|AA) (N|M|NG) (S|SH|Z|TH) (IY|IH|IX) (EY|EH|IY|AY) (SH|S|ZH|CH) (AH|AE|ER|AA) (N|M|NG) (W|L|Y) (IH|IY|AX|EH) (TH|S|DH|F|HH) (M|N) (AO|AA|ER|AX|UH) (R|Y|L) (K|G|T|HH) (AA|AH|ER|AO) (N|M|NG) (F|HH|TH|V) (AH|AE|ER|AA) (D|T|JH|G|B) (AH|AE|ER|AA) (N|M|NG) (S|SH|Z|TH) SIL);
The accuracy for this method of edit distance scoring was 30/41 (73.2%) -- the more contextual information provided, better the accuracy.
Here is some sample output, written both one below the other to have a comparison of phonemes.
Forced-alignment output:
AH P R OW CH DH AH T IY CH IH NG AH V P R AH N AH N S IY EY SH AH N W IH TH M
Decoder output:
ER P R UH JH DH AH CH IY CH IY N AH V P R ER N AH NG Z IY EY SH AH N W IH TH M
In this case, both are forced outputs. So, if someone skips or inserts something during phrase recording, it may not work well. We need to think a method to solve this. Will a separate pass decoder grammar to test for whole word or syllable insertions and deletions work?
Things to do for next week:
1. We are trying to combine acoustic standard scores (and duration) from forced alignment with an edit distance scoring grammar, which was reported to have better correspondence with human expert phonologists.
2. Complete a basic demo of the pronunciation evaluation without edit distance scoring from exemplar recordings using conversion of phoneme acoustic scores and durations to normally distributed scores, and then using those to derive their means and standard deviations, so we can produce per-phoneme acoustic and duration standard scores for new uploaded recordings.
3. Finalize the method for mispronunciation detection at phoneme and word level.
Automating the creation of joint multigram language models as WFST
(author: John Salatas)
Foreword
Previous articles have introduced the C++ code to align a pronounciation dictionary [1] and how this aligned dictionary can be used in combination with OpenGrm Ngram Library for the encoding of joint multigram language models as WFST [2]. This article will describe the automation of the language model creation procedures as a complete C++ application that is simpler to use than the original procedures described in [2].
1. Installation
The procedure below is tested on an Intel CPU running openSuSE 12.1 x64 with gcc 4.6.2. Further testing is required for other systems (MacOSX, Windows).
The code requires the openFST library to be installed on your system. Having downloaded, compiled and installed openFST, the first step is to checkout the code from the cmusphinx SVN repository:
$ svn co https://cmusphinx.svn.sourceforge.net/svnroot/cmusphinx/branches/g2p/train
and compile it
$ cd train
$ make
g++ -c -g -o src/train.o src/train.cpp
g++ -c -g -o src/phonetisaurus/M2MFstAligner.o src/phonetisaurus/M2MFstAligner.cpp
g++ -c -g -o src/phonetisaurus/FstPathFinder.o src/phonetisaurus/FstPathFinder.cpp
g++ -g -L/usr/local/lib64/fst -lfst -lfstfar -lfstfarscript -ldl -lngram -o train src/train.o src/phonetisaurus/M2MFstAligner.o src/phonetisaurus/FstPathFinder.o
$
2. Usage
Having compiled the script, running it without any command line arguments will print out it's usage:
$ ./train
Input file not provided
Usage: ./train [--seq1_del] [--seq2_del] [--seq1_max SEQ1_MAX] [--seq2_max SEQ2_MAX]
[--seq1_sep SEQ1_SEP] [--seq2_sep SEQ2_SEP] [--s1s2_sep S1S2_SEP]
[--eps EPS] [--skip SKIP] [--seq1in_sep SEQ1IN_SEP] [--seq2in_sep SEQ2IN_SEP]
[--s1s2_delim S1S2_DELIM] [--iter ITER] [--order ORDER] [--smooth SMOOTH]
[--noalign] --ifile IFILE --ofile OFILE
--seq1_del, Allow deletions in sequence 1. Defaults to false.
--seq2_del, Allow deletions in sequence 2. Defaults to false.
--seq1_max SEQ1_MAX, Maximum subsequence length for sequence 1. Defaults to 2.
--seq2_max SEQ2_MAX, Maximum subsequence length for sequence 2. Defaults to 2.
--seq1_sep SEQ1_SEP, Separator token for sequence 1. Defaults to '|'.
--seq2_sep SEQ2_SEP, Separator token for sequence 2. Defaults to '|'.
--s1s2_sep S1S2_SEP, Separator token for seq1 and seq2 alignments. Defaults to '}'.
--eps EPS, Epsilon symbol. Defaults to ''.
--skip SKIP, Skip/null symbol. Defaults to '_'.
--seq1in_sep SEQ1IN_SEP, Separator for seq1 in the input training file. Defaults to ''.
--seq2in_sep SEQ2IN_SEP, Separator for seq2 in the input training file. Defaults to ' '.
--s1s2_delim S1S2_DELIM, Separator for seq1/seq2 in the input training file. Defaults to ' '.
--iter ITER, Maximum number of iterations for EM. Defaults to 10.
--ifile IFILE, File containing training sequences.
--ofile OFILE, Write the binary fst model to file.
--noalign, Do not align. Assume that the aligned corpus already exists.
Defaults to false.
--order ORDER, N-gram order. Defaults to 9.
--smooth SMOOTH, Smoothing method. Available options are:
"presmoothed", "unsmoothed", "kneser_ney", "absolute",
"katz", "witten_bell", "unsmoothed". Defaults to "kneser_ney".
$
As in [1], the two required options are the pronunciation dictionary (IFILE) and the file in which the binary fst model will be saved (OFILE). The script provide default values for all other options and an fst binary model for cmudict (v. 0.7a) can be created simply by the following command
$ ./train --seq1_del --seq2_del --ifile
allowing for deletions in both graphemes and phonemes, and
$ ./train --ifile
not allowing for deletions.
3. Performance, Evaluation and Comparison with phonetisaurus
in order to test the new code's performance, tests similar to those in [1] and [2] where performed, with similar results in both resource utilization and it's ability to generate pronunciations for previously unseen words.
4. Conclusion - Future Works
Having integrated the model training procedure into a simplified application, combined with the dictionary alignment code, the next step would be to create the evaluation code in order to avoid using phonetisaurus evaluate python script. Further steps include the writing of the necessary code to load the WFST binary model in java code, and convert it to the java's implementation of openFST [3], [4].
References
[1] Porting phonetisaurus many-to-many alignment python script to C++.
[2] Using OpenGrm NGram Library for the encoding of joint multigram language models as WFST.
[3] Porting openFST to java: Part 1.
[4] Porting openFST to java: Part 2.