Porting openFST to java: Part 1
(author: John Salatas)
Foreword
This article is the first part of a series of articles on porting openFST[1] in java. OpenFST is an open-source C++ library for weighted finite-state transducers (WFSTs) [1] and having a similar java implementation is a crucial first step for the integration of phonetisaurus g2p into sphinx 4 [2]
This article will briefly review some mathematical background of weighted finite-state transducers describe the current implementation of openFST and then start describing the java implementation which will be completed in articles that will follow.
1. Weighted finite-state transducers
Weighted finite-state transducers have been used in speech recognition and synthesis, machine translation, optical character recognition, pattern matching,string processing, machine learning, information extraction and retrieval among others. Having a comprehensive software library of weighted transducer representations and core algorithms is key for using weighted transducers in these applications and for the development of new algorithms and applications. [1]
A weighted finite-state transducer (WFST) is a finite automaton for which each transition has an input label, an output label, and a weight. Figure 1 depicts a weighted finite state transducer: [1]
[caption id="attachment_339" align="aligncenter" width="497" caption="Figure 1: Example weighted finite-state transducer"]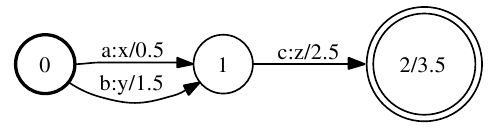 [/caption]
[/caption]
The initial state is labeled 0. The final state is 2 with final weight of 3.5. Any state with non-infinite final weight is a final state. There is a transition from state 0 to 1 with input label a, output label x, and weight 0.5. This machine transduces, for instance, the string ac to xz with weight 6.5 (the sum of the arc and final weights). [1]
The weights may represent any set so long as they form a semiring. A semiring $latex (\mathbb{K}, \oplus, \otimes, \bar{0}, \bar{1}) $ is specified by a set of values $latex \mathbb{K} $, two binary operations $latex \oplus $ and $latex \otimes $, and two designated values $latex \bar{0} $ and $latex \bar{1} $. The operation $latex \oplus $ is associative, commutative, and has $latex \bar{0} $ as identity. The operation $latex \otimes $ is associative, has identity $ and $latex \bar{1} $, distributes with respect to $latex \oplus $, and has $latex \bar{0} $ as annihilator: for all $latex a \in \mathbb{K} , a \otimes \bar{0} = \bar{0} \otimes a = \bar{0} $. If $latex \otimes $ is also commutative, we say that the semiring is commutative. [1]
Table 1 below lists some common semirings. All but the last are defined over subsets of the real numbers (extended with positive and negative infinity). In addition to the familiar Boolean semiring, and the probability semiring used to combine probabilities, two semirings often used in applications are the log semiring which is isomorphic to the probability semiring via the negative-log mapping, and the tropical semiring which is similar to the log semiring except the operation is min. The left (right) string semiring, which is defined over strings, has longest common prefix (suffix) and concatenation as its operations, and has the (extended element) infinite string and the empty string for its identity elements. It only distributes on the left (right). [1]
[caption id="attachment_355" align="aligncenter" width="347" caption="Table 1: Semiring examples."]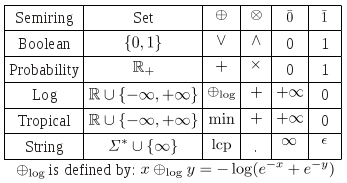 [/caption]
[/caption]
2. The openFST C++ library: Representation and Construction
The motivation for OpenFst was to create a library as comprehensive and efficient as the AT&T FSM [3] Library, but that was an open-source project. We also sought to make this library as flexible and customizable as possible given the wide range of applications WFSTs have enjoyed in recent years. It is a C++ template library, allowing it to be both very customizable and efficient. [1]
In the OpenFst Library, a transducer can be constructed from either the C++ level using class constructors and mutators or from a shell-level program using a textual file representation. [1]
In order to create a transducer using openFST we need first to construct an empty VectorFst: [1]
// A vector FST is a general mutable FST
VectorFst fst;
The VectorFst, like all transducer representations and algorithms in this library, is templated on the transition type. This permits customization of the labels, state IDs and weights in a transducer. StdArc defines the library-standard transition representation:
template
class ArcTpl {
public:
typedef W Weight;
typedef int Label;
typedef int StateId;
ArcTpl(Label i, Label o, const Weight& w, StateId s)
: ilabel(i), olabel(o), weight(w), nextstate(s) {}
ArcTpl() {}
static const string &Type(void) {
static const string type =
(Weight::Type() == "tropical") ? "standard" : Weight::Type();
return type;
}
Label ilabel;
Label olabel;
Weight weight;
StateId nextstate;
};
A Weight class holds the set element and provides the semiring operations. Currently openFST provides many different C++ Template-based implementations like TropicalWeightTpl, LogWeightTpl and MinMaxWeightTpl which extend a base FloatWeightTpl (see float-weight.h for implementation details) and others. Having these Template-based implementations opeFST we need just have a typedef to define a particular Weight such as TropicalWeight:
// Single precision tropical weight
typedef TropicalWeightTpl TropicalWeight;
3. The proposed FST java library
Based on the above description and on technical implementation differences between C++ and Java, and more specific mostly on a) difference between C++ Templates and Java generics [4] and b) the lack of operation overloads in Java, the initial implementation includes the edu.cmu.sphinx.fst.weight.Weight
There is also a generics based interface edu.cmu.sphinx.fst.weight.Semiring
Finaly the edu.cmu.sphinx.fst.demos.basic package contains a main class for testing the above functionality by instatiating a TropicalSemiring and performing some operations on various Weight values.
4. Conclusion – Future work
This article tried to describe some basic theoritical background on weighted finite-state transducers, provide a brief description on the openFST architect and foundation classes and finally presented an initial design for the FST java library implementation. Following the general open-source philosophy “perform small commits often” the library is available in CMUShinx' repository created for the integration of phonetisaurus g2p into sphinx 4. [5]
The next steps is to provide the Arc and Fst classes which over time will be extended to provide the required functionality for the various FST operations needed for my GSoC 2012 project. Hopefully, over time, more functionality will be provided by the community.
References
[1] C. Allauzen, M. Riley, J. Schalkwyk, W. Skut, M. Mohri, “OpenFst: a general and efficient weighted finite-state transducer library”, Proceedings of the 12th International Conference on Implementation and Application of Automata (CIAA 2007), pp. 11–23, Prague, Czech Republic, July 2007.
[2] J. Salatas, “Phonetisaurus: A WFST-driven Phoneticizer – Framework Review”, last accessed: 08/05/2012.
[3] M. Mohri, F. Pereira, M. Riley, “The Design Principles of a Weighted Finite-State Transducer Library”, Theoretical Computer Science, pp. 15-32, 2000.
[4] H. M. Qusay, “Using and Programming Generics in J2SE 5.0”, Oracle Technology Network, 2004, last accessed: 08/05/2012.
Phonetisaurus: A WFST-driven Phoneticizer – Framework Review
(author: John Salatas)
Foreword
This article tries to analyze the phonetisaurus g2p [1], [2] code by describing it's main parts and algorithms behind these. Phonetisaurus is a modular system and includes support for several third-party components. The system has been implemented primarily in python, but also leverages the OpenFST framework [3].
1. Overall Architecture
The procedure for model training and evaluation in phonetisaurus consists by three parts [4]: the dictionary alignment, the model training and finally the evaluation of the model.
1.1. Dictionary Alignment
Manual G2P alignments are generally not available, thus it is necessary to first align the grapheme and phoneme sequences in a pronunciation dictionary, prior to building a pronunciation model. Phonetisaurus utilizes the EM-based many-to-many alignment procedure detailed in [5] that supports alignments from digraphs such as “sh” to a single phoneme, or the reverse case. Recently the dictionary alignment was reimplemented and upgraded using OpenFst.
The command line script that controls the alignment procedure m2m-aligner.py interfaces with the M2MFstAligner class (M2MFstAligner.cpp) using Swig [6], in order to transform two sequences, one of graphemes and one of phonemes to an FST that encodes all possible alignments between the symbols in the two sequences.
The basic transformation of the sequence
void M2MFstAligner::Sequences2FST( VectorFst* fst, vector* seq1, vector* seq2 );
creates a VectorFst
After the FSTs for all entries are created the procedure continus with the EM algorithm which is implemented in the
void M2MFstAligner::expectation( );
and
float M2MFstAligner::maximization( bool lastiter );
procedures. These procedures utilize the ShortestDistance search operation and the Divide, Times and Plus semiring operations.
1.2. Model Training
The command line script that controls the model training procedure train-model.py uses the estimate-ngram utility of the MIT Language Modeling (MITLM) toolkit [7] in order to estimate an n-gram language model language model by cumulating n-gram count statistics,"smoothing observed counts, and building a backoff n-gram mode [8].
The estimate-ngramm utility produces a language model in ARPA format which is then converted to a FST textual represantion through the use of the arpa2fst.py script. This textual represantion is then parsed by the fstcompile command line utility of OpenFST and converted to the final binary representation.
1.3. Model Evaluation
The command line script that controls the model evaluation procedure evaluate.py utilizes the Phonetisaurus class (Phonetisaurus.cpp), through the phonetisaurus-g2p command line interface, for the g2p conversion, which is then evaluated. It uitilizes the Compose binary operation, Project unary operation, ShortestPath search operation, Times semiring operation and RmEpsilon optimization operation.
A pronunciation for a new word is achieved by compiling the word into a WFSA and composing it with the pronunciation model. The best hypothesis is just the shortest path through the composed WFST. [1]
The input word is converted to an acceptor I which has one arc for each of the characters in the word. I is then composed with M according to O = I ◦ M where ◦ denotes the composition operator. The n-best paths are extracted from O by projecting the output, removing the epsilon labels and applying the n-shortest paths algorithm with determinization. [2]
2. Conclusion – Future Work
This article tried to analyze the phonetisaurus g2p code and its main parts. Having this description will allow us to produce a more accurate and analytical planning and scheduling the tasks required for the integration of phonetisaurus g2p into sphinx 4 for my GSoC 2012 project [9].
References
[1] J. Novak, D. Yang, N. Minematsu, K. Hirose, "Initial and Evaluations of an Open Source WFST-based Phoneticizer", The University of Tokyo, Tokyo Institute of Technology
[2] D. Yang, et. al., “Rapid development of a G2Psystem based on WFST framework”, ASJ 2009
Autumn session, pp. 111-112, 2009.
[3] C. Allauzen, M. Riley, J. Schalkwyk, W. Skut, M. Mohri, "OpenFst: a general and efficient weighted finite-state transducer library", Proceedings of the 12th International Conference on Implementation and Application of Automata (CIAA 2007), pp. 11–23, Prague, Czech Republic, July 2007.
[4] J. Novak, README.txt, phonetisaurus source code, last accessed: 29/04/2012.
[5] S. Jiampojamarn, G. Kondrak, T. Sherif, “Applying Many-to-Many Alignments and Hidden Markov Models to Letter-to-Phoneme Conversion”, NAACL HLT, pp. 372-379, 2007.
[6] Simplified Wrapper and Interface Generator, last accessed: 29/04/2012.
[7] MIT Language Modeling Toolkit, last accessed: 29/04/2012.
[8] D. Jurafsky, J. H. Martin, “Speech and Language Processing”, Prentice Hall, 2000.
[9] J. Salatas, GSoC 2012 Project: Letter to Phoneme Conversion in sphinx4, last accessed: 29/04/2012.
Letter to Phoneme Conversion in CMU Sphinx-4: Literature review
(author: John Salatas)
1. Foreword
Currently Sphinx-4 uses a predefined dictionary for mapping words to sequence of phonemes. I propose modifications in the Sphinx-4 code that will enable it to use trained models (through some king of machine learning algorithm) to map letters to phonemes and thus map words to sequence of phonemes without the need of a predefined dictionary. A dictionary will be only used to train the required models.
2. Literature Review
2.1. Grapheme-to-Phoneme methods
Grapheme to Phoneme (G2P) (or Letter to Sound – L2S) conversion is an active research field with applications to both text-to-speech (TTS) and automated speech recognition (ASR) systems. There are many different approaches used for the G2S conversion proposed by different researchers.
Hein [1] proposes a method that use a feedforward neural network for the G2S conversion process and proposes a simple algorithm for the creation of the grapheme-to-phoneme matching database with a phonetic dictionary as input. The method has been tested in both English and German languages. 99.2% of 305000 entries of the German CELEX could be completely mapped and 91.8% of 59000 entries of the English PRONLEX.
Stoianov et al. [2] propose the use of Simple Recurrent Network (SRN) [3] for learning grapheme-to-phoneme mapping in Dutch. They conclude that SRN performs well on training and unseen test data sets even after very limited number of training epochs. Also, there were significant consistency and frequency effects on error.
Daelemans and Van Den Bosch [4] propose a data-oriented language-independent approach to grapheme-to-phoneme conversion problem. Their method takes as input a set of spelling words with their associative pronunciation, which do not have to be aligned, and produces as its output the phonetic transcription according to the implicit rules in the training dataset. The method is evaluated for the Dutch language with a 95,1% accuracy in unseen words.
Jouvet et al. [5] propose the combination of two g2p converters, one based on joint multigram model (JMM) [6] and one on conditional random fields (CRF) [7] and, furthermore, they evaluate the g2p conversion in a speech recognition context using French broadcast news data and cmusphinx.
The Joint-Multigram Model approach is a state of the art approach for grapheme-to-phoneme conversion [6]. The JMM approach relies on using joint sequences, where each joint sequence is actually composed of a sequence of graphemes and its associated sequence of phonemes. A language model is applied on the joint sequences. The training algorithm aims at determining the optimal set of joint sequences as well as the associated language model. The training proceeds in an incremental way. An initial pass creates a very simple model. Then each new training pass refines the model by enlarging the joint sequences whenever it is relevant to do so (i.e. it optimizes some training criteria). [5]
The CRF-based approach for grapheme-to-phoneme conversion [7],[8] is more recent than the JMM-based approach. It relies on the probabilistic framework and discriminative training offered by CRFs for labeling structured data such as sequences. The advantage of the CRF approach is its ability to handle various features, that is an arbitrary window length of letters, and possibly additional information such as word category. [5]
2.2. The CMU Sphinx-4 speech recognition system
Sphinx-4 [9],[10] is a flexible, modular and pluggable framework to help foster new innovations in the core research of hidden Markov model (HMM) recognition systems. The design of Sphinx-4 is based on patterns that have emerged from the design of past systems as well as new requirements based on areas that researchers currently want to explore. To exercise this framework, and to provide researchers with a ”research-ready” system, Sphinx-4 also includes several implementations of both simple and state-of-the-art techniques. The framework and the implementations are all freely available via open source. [9]
The Sphinx-4 architecture has been designed with a high degree of modularity. Figure 1 shows the overall architecture of the system. Even within each module shown in Figure 1, the code is extremely modular with easily replaceable functions. [10]
[caption id="attachment_320" align="aligncenter" width="428" caption="Figure 1: Architecture of the Sphinx-4 system. The main blocks are Frontend, Decoder and Knowledge base. Except for the blocks within the KB, all other blocks are independently replaceable software modules written in Java. Stacked blocks indicate multiple types which can be used simultaneously"]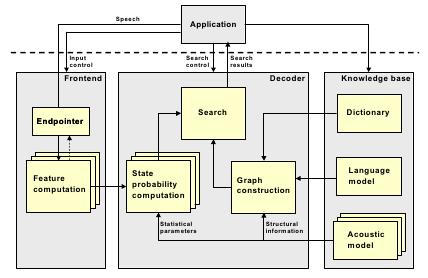 [/caption]
[/caption]
3. Initial Implementation Considerations
Regarding the CRF models, there is already a java implementation [11] which is based on the original CRF paper by J. Lafferty et al [12].
For the JMM models, there are many different approaches proposed [6], [13], [14] and all of them provide the implementation code (in C++/python) as free software available at [15], [16] and [17] respectively.
Another point regarding the JMM models, is the implementation of Weighted Finite State Transducers in java. Two possible approaches would be to a) either reimplement OpenFST Library [18] in java (it is written in C++) or b) investigate if the classes under the fst package [19] of the MARY Text-to-Speech System [20] can be easily integrated in cmusphinx, or if it can just be the basis for a new WFST implementation in Java.
4. Conclusion – Future work
The modular architecture of Sphinx-4 allows for experimentation in emerging areas of research and gives the ability to researchers to easily replace most of it's parts.
On a recent paper [21] Jouvet et al. propose the combination of two g2p converters, one based on joint multigram model (JMM) and one on conditional random fields (CRF). They evaluate the g2p conversion in a speech recognition context using French broadcast news data and cmusphinx.
During the Google Summer of Code 2012, I will follow a similar approach as in the above paper in order to evaluate and implement the necessary code for g2p conversion in sphinx-4.
You can follow my progress by subscribing to my project's blog feeds [22]
References
[1] H. U. Hein, “Automation of the training procedures for neural networks performing multi-lingual grapheme to phoneme conversion”, EUROSPEECH'99, pp. 2087-2090, 1999.
[2] I. Stoianov, L. Stowe, and J. Nerbonne, “Connectionist learning to read aloud and correlation to human data”, Proceedings of the 21st Annual Conference of the Cognitive Science Society. Hillsdale, NJ: Erlbaum, 1999.
[3] J.L. Elman, “Finding structure in time”, Cognitive Science, 14, pp. 213-252, 1990.
[4] W. Daelemans, A. V.D. Bosch, "Language-independent data-oriented grapheme-to-phoneme conversion", Progress in Speech Synthesis, pp. 77–89. New York, USA, 1997.
[5] D. Jouvet, D. Fohr, I. Illina, "Evaluating Grapheme-to-Phoneme Converters in Automatic Speech Recognition Context", IEE International Conference on Acoustics, 2012.
[6] M. Bisani, H. Ney, "Joint-sequence models for grapheme-to-phoneme conversion", Speech Communications, vol. 50, no. 5, 2008.
[7] D. Wang, S. King, "Letter-to-sound Pronunciation Prediction Using Conditional Random Fields", IEEE Signal Processing Letters, vol. 18, no. 2, pp. 122-125, 2011.
[8] I. Illina, D. Fohr & D. Jouvet, "Grapheme-to-Phoneme Conversion using Conditional Random Fields", in Proc. INTERSPEECH'2011, Florence, Italy, Aug. 2011.
[9] W. Walker, P. Lamere, P. Kwok, B. Raj, R. Singh, E. Gouvea, P. Wolf, and J. Woelfel, “Sphinx-4: A flexible open source framework for speech recognition”, Technical Report SMLI TR2004-0811, Sun Microsystems Inc., 2004.
[10] P. Lamere, P. Kwok, W. Walker, E. Gouvea, R. Singh, B. Raj, and P. Wolf, “Design of the CMU Sphinx-4 decoder”, Proceedings of the 8th European Conference on Speech Communication and Technology, Geneve, Switzerland, pp. 1181–1184, Sept. 2003.
[11] “CRF Project Page”, last accessed: 24/04/2012
[12] J. Lafferty, A. McCallum, F. Pereira, “Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data”, Proceedings of the International Conference on Machine Learning (ICML-2001),2001.
[13] “Phonetisaurus g2p tutorial”, last accessed: 25/04/2012
[14] S. Jiampojamarn, C. Cherry, G. Kondrak, “Joint Processing and Discriminative Training for Letter-to-Phoneme Conversion”, Proceeding of the Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (ACL-08: HLT), pp.905-913, Columbus, OH, June 2008.
[15] “Sequitur G2P, A trainable Grapheme-to-Phoneme converter”, last accessed: 25/04/2012
[16] “phonetisaurus: A WFST-driven Phoneticizer”, last accessed: 25/04/2012
[17] “DirecTL+ : String transduction model”, http://code.google.com/p/directl-p/ last accessed: 25/04/2012
[18] “OpenFST Library”, last accessed: 25/04/2012
[19] “Javadoc for package marytts.fst”, last accessed: 25/04/2012
[20] “The MARY Text-to-Speech System”, last accessed: 25/04/2012
[21] D. Jouvet, D. Fohr, I. Illina, "Evaluating Grapheme-to-Phoneme Converters in Automatic Speech Recognition Context", IEE International Conference on Acoustics, 2012
[22] “GSoC 2012: Letter to Phoneme Conversion in CMU Sphinx-4”, Project progress updates.